As announced in the previous blog post, I have been writing a paper about the security big data lake. A topic that starts coming up with more and more organizations lately. Unfortunately, there is a lot uncertainty around the term so I decided to put some structure to the discussion.
Download the paper here.
A little teaser from the paper: The following table from the paper summarizes the four main building blocks that can be used to put together a SIEM – data lake integration:
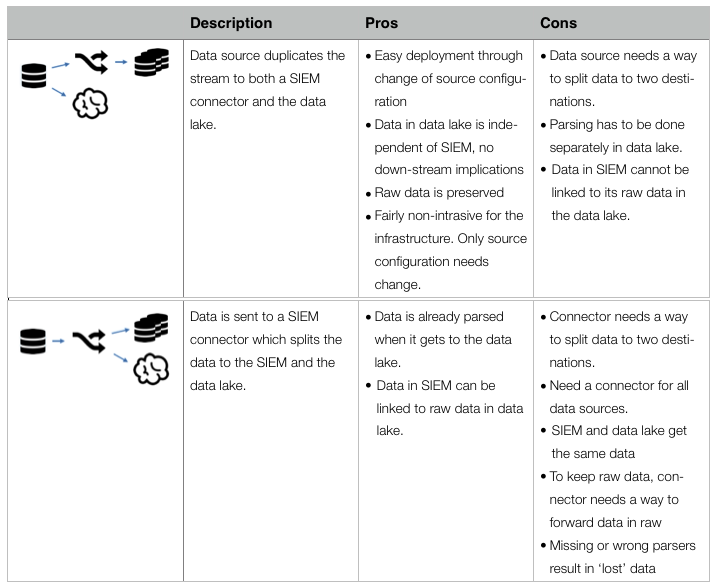
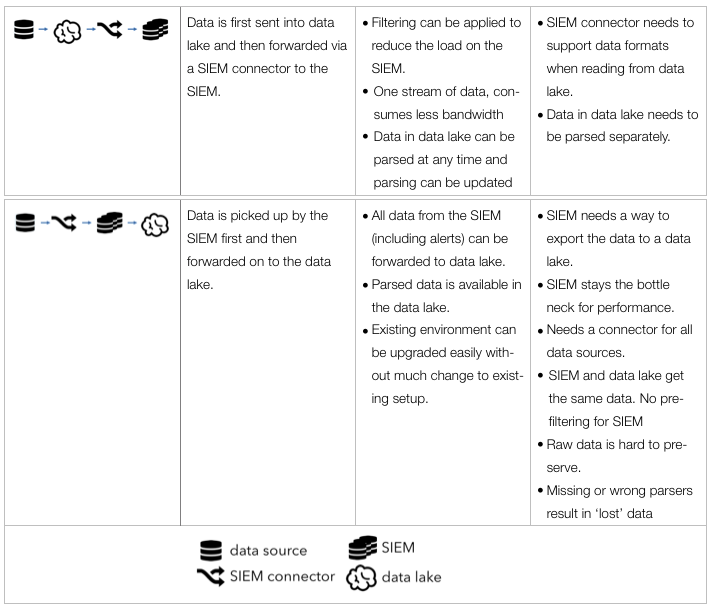
Thanks @antonchuvakin for brainstorming and coming up with the diagram.
Information security has been dealing with terabytes of data for over a decade; almost two. Companies of all sizes are realizing the benefit of having more data available to not only conduct forensic investigations, but also pro-actively find anomalies and stop adversaries before they cause any harm.
UPDATE: Download the paper here
I am finalizing a paper on the topic of the security big data lake. I should have the full paper available soon. As a teaser, here are the first two sections:
What Is a Data Lake?
The term data lake comes from the big data community and starts appearing in the security field more often. A data lake (or a data hub) is a central location where all security data is collected and stored. Sounds like log management or security information and event management (SIEM)? Sure. Very similar. In line with the Hadoop big data movement, one of the objectives is to run the data lake on commodity hardware and storage that is cheaper than special purpose storage arrays, SANs, etc. Furthermore, the lake should be accessible by third-party tools, processes, workflows, and teams across the organization that need the data. Log management tools do not make it easy to access the data through standard interfaces (APIs). They also do not provide a way to run arbitrary analytics code against the data.
Just because we mentioned SIEM and data lakes in the same sentence above does not mean that a data lake is a replacement for a SIEM. The concept of a data lake merely covers the storage and maybe some of the processing of data. SIEMs are so much more.
Why Implementing a Data Lake?
Security data is often found stored in multiple copies across a company. Every security product collects and stores its own copy of the data. For example, tools working with network traffic (e.g., IDS/IPS, DLP, forensic tools) monitor, process, and store their own copies of the traffic. Behavioral monitoring, network anomaly detection, user scoring, correlation engines, etc. all need a copy of the data to function. Every security solution is more or less collecting and storing the same data over and over again, resulting in multiple data copies.
The data lake tries to rid of this duplication by collecting the data once and making it available to all the tools and products that need it. This is much simpler said than done. The core of this document is to discuss the issues and approaches around the lake.
To summarize, the four goals of the data lake are:
- One way (process) to collect all data
- Process, clean, enrich the data in one location
- Store data once
- Have a standard interface to access the data
One of the main challenges with this approach is how to make all the security products leverage the data lake instead of collecting and processing their own data. Mostly this means that products have to be rebuilt by the vendors to do so.
Have you implemented something like this? Email me or put a comment on the blog. I’d love to hear your experience. And stay tuned for the full paper!
