June 21, 2015
I have been using MonetDB for a month now and have to say, I really like it. MonetDB is a columnar data store and it’s freaking fast.
However, when I started using it, I wasn’t on very good terms with my database. Here are the three things you have to know when you use MonetDB:
- Strings are quoted with single quotes. NOT double quotes! For example:
SELECT * FROM table where field like '%foo';
- Field names that are special terms need to be double quoted! There are many special terms, such as: “range”, “external”, “end”, … For example:
SELECT "end", other FROM table;
- The WHERE clause in a GROUP by statement is called HAVING (that’s just basic SQL knowledge, but good to remember): For example:
SELECT * FROM table GROUP BY field HAVING field>500;
- Querying an INET datatype needs to convert a STRING to an INET in the query as well:
SELECT * FROM table WHERE ip=inet '10.0.0.2';
or even cooler:
SELECT * FROM table WHERE ip<<inet '10.2.0.0/16';
- MonetDB has schemas. They are almost like different databases if you want. You can switch schema by using:
set schema foo;
- Inserting millions of records is fastest with the COPY INTO command:
cat file | mclient -d databse -s "COPY INTO table FROM STDIN using delimiters '\t' " -
- And here is how you create your own database and user:
sudo monetdb create _database_ -p _password_
sudo monetdb release _database_
mclient -u monetdb -d _database_
alter user set password '_password_' using old password 'monetdb';
create user "_username_" with password '_password_' name '_name_' schema "sys";
create schema "_your_schema_" authorization "_username_";
alter user _username_ set schema "_your_schema_";
I hope these things will help you deal with MonetDB a bit easier. The database is worth a try!!
September 17, 2014
A new version of AfterGlow is ready. Version 1.6.5 has a couple of improvements:
1. If you have an input file which only has two columns, AfterGlow now automatically switches to a two-node mode. You don’t have to use the (-t) switch explicitly anymore in this case! (I know, it’s about time I added this)
2. Very minor change, but something that kept annoying me over time is the default edge length. It was set to 3 initially and now it’s reduced to 1.5, which makes fro a bit more compact graphs. You can still change this with the -e switch on the command line
3. The major change is about adding edge label though. Here is a quick example:
label.edge=$fields[2]
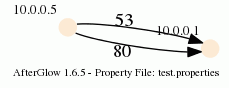
This assumes that the third column of your data contains the label for the data. In the example below, the port numbers:
10.0.0.5,10.0.0.1,53
10.0.0.5,10.0.0.1,80
When you run afterglow, use the -t switch to have it render only two nodes, but given the configuration above, we are using the third column as the edge label. The output will look like this:

As you can see, we have twice the same edge defined in the data with two different labels (port 53 and 80). If you want to have the graph show both edges, you add the following configuration in the configuration file:
label.duplicate=1
Which then results in the following graph:
Note that the duplicating of edges only works with GDF files (-k). The edge labels work in DOT and GDF files, not in GraphSON output.
March 24, 2012
 There are cases where you need fairly sophisticated logic to visualize data. Network graphs are a great way to help a viewer understand relationships in data. In my last blog post, I explained how to visualize network traffic. Today I am showing you how to extend your visualization with some more complicated configurations.
There are cases where you need fairly sophisticated logic to visualize data. Network graphs are a great way to help a viewer understand relationships in data. In my last blog post, I explained how to visualize network traffic. Today I am showing you how to extend your visualization with some more complicated configurations.
This blog post was inspired by an AfterGlow user who emailed me last week asking how he could keep a list of port numbers to drive the color in his graph. Here is the code snippet that I suggested he use:
variable=@ports=qw(22 80 53 110);
color="green" if (grep(/^\Q$fields[0]\E$/,@ports))
Put this in a configuration file and invoke AfterGlow with it:
perl afterglow.pl -c file.config | ...
What this does is color all nodes green if they are part of the list of ports (22, 80, 53, 110). I am using $fields[0] to reference the first column of data. You could also use the function fields() to reference any column in the data.
Another way to define the variable is by looking it up in a file. Here is an example:
variable=open(TOR,"tor.csv"); @tor=; close(TOR);
color="red" if (grep(/^\Q$fields[1]\E$/,@tor))
This time you put the list of items in a file and read it into an array. Remember, it’s just Perl code that you execute after the variable= statement. Anything goes!
I am curious what you will come up with. Post your experiments and questions on secviz.org!
Read more about how to use AfterGlow in security visualization.
September 8, 2011
 Analyzing log files can be a very time consuming process and it doesn’t seem to get any easier. In the past 12 years I have been on both sides of the table. I have analyzed terabytes of logs and I have written a lot of code that generates logs. When I started writing Loggly’s middleware, I thought it was going to be really easy and fun to finally write the perfect application logs. Guess what, I was wrong. Although I have seen pretty much any log format out there, I had the hardest time coming up with a decent log format for ourselves. What’s a good log format anyways? The short answer is: “One that enables analytics or actions.”
Analyzing log files can be a very time consuming process and it doesn’t seem to get any easier. In the past 12 years I have been on both sides of the table. I have analyzed terabytes of logs and I have written a lot of code that generates logs. When I started writing Loggly’s middleware, I thought it was going to be really easy and fun to finally write the perfect application logs. Guess what, I was wrong. Although I have seen pretty much any log format out there, I had the hardest time coming up with a decent log format for ourselves. What’s a good log format anyways? The short answer is: “One that enables analytics or actions.”
I was sufficiently motivated to come up with a good log format that I decided to write a paper about application logging guidelines. The paper has two main parts: Logging Guidelines and a reference architecture for a cloud service. In the first part I am covering the questions of when to log, what to log, and how to log. It’s not as easy as you might think. The most important thing to constantly keep in mind is the use of the logs. Especially for the question on what to log you need to keep the log consumer in mind. Are the logs consumed by a human? Are they consumed by a log management tool? What are the people looking at the logs trying to do? Debugging the application? Monitoring performance? Detecting security violations? Depending on the answers to these questions, you might change the places in your code that you emit log records. (Or even better you log in all places and add a use-case indicator as a field to your logs.)
The paper is a starting point and not a definite guide. I would expect readers to challenge it and come up with improvements and refinements of use-cases and also the exact contents of the log records. I’d love to hear from practitioners and get a dialog going.
As a side note: CEE, the Common Event Expression standard, covers parts of what I am talking about in the paper. However, the paper’s focus is mainly on defining guidelines for application developers; establishing a baseline of when log entries should be recorded and what information should be included.
Resources: Cloud Application Logging for Forensics – Paper – Presentation
May 25, 2010
I thought you might be interested in some blog posts that I have written lately. I have been doing quite a bit of work on Django and Web applications. That might explain the topics of my recent blog posts. Check them out.
Would love to hear from you if you have any comments. Either leave a comment on the blogs, or contact me via Twitter at @zrlram.
February 24, 2007
By now you should know that I really like command line tools which operate well when applied to data through a pipe. I have posted quite a few tips already to do data manipulation on the command line. Today I wanted a quick way to lookup IP address locations and add them to a log file. After investigating a few free databases, I came accross Geo::IPFree, a Perl library which does the trick. So here is how you add the country code. First, this is the format of my log entries:
10/13/2005 20:25:54.032145,195.141.211.178,195.131.61.44,2071,135
I want to get the country of the source address (first IP in the log). Here we go:
cat pflog.csv | perl -M'Geo::IPfree' -na -F/,/ -e '($country,$country_name)=Geo::IPfree::LookUp($F[1]);chomp; print "$_,$country_name\n"'
And here the output:
10/13/2005 20:24:33.494358,62.245.243.139,212.254.111.99,,echo request,Europe
Very simple!
May 19, 2006
I was fiddling with optimizing AfterGlow the other day and to do so, I introduced caches for some of the functions. Later a coworker (thanks Senthil) sent me a note that I could have done without implementing the cache myself by using Memoize. This is how to use it:
use Memoize;
memoize(function);
function(arguments); # this is now much faster
This will basically cache the outputs for each of inputs to the function. Especially for recursion this is an incredible speedup.
April 4, 2006
I was working on AfterGlow the other night and I realized that adding feature after feature starts to slow down the thing quite a bit (you need to be a genious to figure that one out!). So that prompted me to look for Perl performance analyzers and indeed I found something that’s pretty useful.
Run your perl script with: perl -d:DProf and then run dprofpp. This will show you how much time was spent in each of the subroutines. It helped me pinpoint that most of the time was spent in the getColor() call. The logical solution was to introduce a cache for the colors and guess what – AfterGlow 1.5.1 will be faster 😉
This is a sample output of dprofpp:
Total Elapsed Time = 11.69959 Seconds
User+System Time = 8.969595 Seconds
Exclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
81.5 7.310 9.900 120000 0.0001 0.0001 main::getColor
29.1 2.615 2.615 116993 0.0000 0.0000 main::subnet
0.89 0.080 0.080 20000 0.0000 0.0000 main::getEventName
0.22 0.020 0.020 20000 0.0000 0.0000 main::getSourceName
0.22 0.020 0.020 20000 0.0000 0.0000 main::getTargetName
0.11 0.010 0.010 1 0.0100 0.0100 main::BEGIN
0.00 - -0.000 1 - - Exporter::import
0.00 - -0.000 1 - - Getopt::Std::getopts
0.00 - -0.000 1 - - main::propertyfile
0.00 - -0.000 1 - - main::init
- - -0.025 116993 - - main::field
December 4, 2005
The RedHat Magazine had a nice Introduction to Python. Cool example that uses pyGTK!
