Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
Asset management is one of the core components of many successful security programs. I am an advisor to Panaseer, a startup in the continuous compliance management space. I recently co-authored a blog post on my favorite security metric that is related to asset management:
How many assets are in the environment?
A simple number. A number that tells a complex story though if collected over time. A metric also that has a vast number of derivatives that are important to understand and one that has its challenges to be collected correctly. Just think about how you’d know how many assets there are at every moment in time? How do you collect that information in real-time?
The metric is also great to start with to then break it down along additional dimensions. For example:
How many assets are managed versus unmanaged (e.g., IOT devices)
Who are the owners of the assets and how many assets can we assign an owner for?
What does the metric look like broken down by operating system, by business unit, by department, by assets that have control violations, etc.
Where is the asset located?
Who is using the asset?
And then, as with any metric, we can look at the metrics not just as a single instance in time, but we can put them into context and learn more about our asset landscape:
How does the number behave over time? Any trends or seasonalities?
Can we learn the uncertainty associated with the metric itself? Or in other terms, what’s the error range?
Can we predict the asset landscape into the future?
Are there certain behavioral patterns around when we see the assets on the network?
I am just scratching the surface of this metric. Read the full blog post to learn more and explore how continuous compliance monitoring can help you get your IT environment under control.
I recently wrote a post about the concept of the Data Lakehouse, which in some ways, brings components of what I outlined in the first post around my desires for a new database system to life. In this post, I am going to make an attempt to describe a roll-up of some recent big data developments that you should be aware of.
Let’s start with the lowest layer in the database or big data stack, which in many cases is Apache Spark as the processing engine powering a lot of the big data components. The component itself is obviously not new, but there is an interesting feature that was added in Spark 3.0, which is the Adaptive Query Execution (AQE). This features allows Spark to optimize and adjust query plans based on runtime statistics collected while the query is running. Make sure to turn it on for SparkSQL (spark.sql.adaptive.enabled) as it’s off by default.
The next component of interest is Apache Kudu. You are probably familiar with parquet. Unfortunately, parquet has some significant drawbacks, like it’s innate batch approach (you have to commit written data before it’s available for read). Specifically when it comes to real-time applications. Kudu’s on-disk data format closely resembles parquet, with a few differences to support efficient random access as well as updates. Also notable is that Kudu can’t use cloud object storage due to it’s use of Ext4 or XFS and the reliance on a consensus algorithm which isn’t supported in cloud object storage (RAFT).
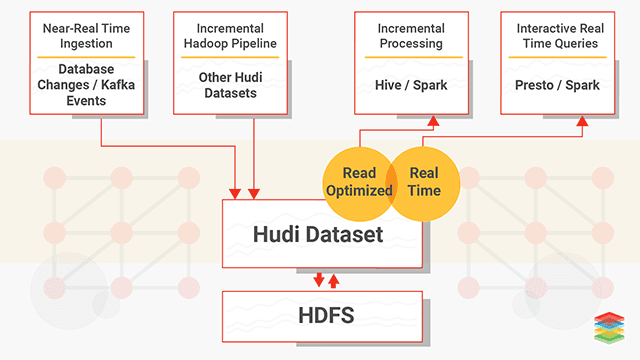
At the same layer in the stack as Kudu and parquet, we have to mention Apache Hudi. Apache Hudi, like Kudu, brings stream processing to big data by providing fresh data. Like Kudu it allows for updates and deletes. Unlike Kudu though, Hudi doesn’t provide a storage layer and therefore you generally want to use parquet as its storage format. That’s probably one of the main differences, Kudu tries to be a storage layer for OLTP whereas Hudi is strictly OLAP. Another powerful feature of Hudi is that it makes a ‘change stream’ available, which allows for incremental pulling. With that it supports three types of queries:
Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action. Here the concepts of ‘copy on write’ and ‘merge on read’ become important. The latter being useful for near real-time querying.
Incremental Queries : Queries only see new data written to the table, since a given commit/compaction.
Read Optimized Queries : Queries see the latest snapshot of table as of a given commit/compaction action. This is mostly used for high speed querying.
The Hudi documentation is a great spot to get more details. And here is a diagram I borrowed from XenoStack:
What then is Apache Iceberg and the Delta Lake then? These two projects yet another way of organizing your data. They can be backed by parquet, and each differ slightly in the exact use-cases and how they handle data changes. And just like Hudi, they both can be used with Spark and Presto or Hive. For a more detailed discussion on the differences, have a look here and this blog walks you through an example of using Hudi and Delta Lake.
Enough about tables and storage formats. While they are important when you have to deal with large amounts of data, I am much more interested in the query layer.
The project to look at here is Apache Calcite which is a ‘data management framework’ or I’d call it a SQL engine. It’s not a full database mainly due to omitting the storage layer. But it supports multiple storage engines. Another cool feature is the support for streaming and graph SQL. Generally you don’t have to bother with the project as it’s built into a number of the existing engines like Hive, Drill, Solr, etc.
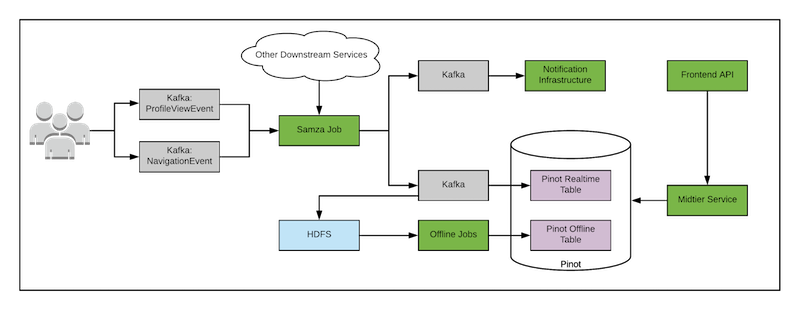
As a quick summary and a slightly different way of looking at why all these projects mentioned so far have come into existence, it might make sense to roll up the data pipeline challenge from a different perspective. Remember the days when we deployed Lambda architectures? You had two separate data paths; one for real-time and one for batch ingest. Apache Flink can help unify these two paths. Others, instead of rewriting their pipelines, let developers write the batch layer and then used Calcite to automatically translate that into the real-time processing code and to merge the real-time and batch outputs, used Apache Pinot.
The nice thing is that there is a Presto to Pinot connector, allowing you to stay in your favorite query engine. Sidenote: don’t worry about Apache Samza too much here. It’s another distributed processing engine like Flink or Spark.
Enough of the geekery. I am sure your head hurts just as much as mine, trying to keep track of all of these crazy projects and how they hang together. Maybe another interesting lens would be to check out what AWS has to offer around databases. To start with, there is PartiQL. In short, it’s a SQL-compatible query language that enables querying data regardless of where or in what format it is stored; structured, unstructured, columnar, row-based, you name it. You can use PartiQL within DynamoDB or the project’s REPL. Glue Elastic views also support PartiQL at this point.
Well, I get it, a general purpose data store that just does the right thing, meaning it’s fast, it has the correct data integrity properties, etc, is a hard problem. Hence the sprawl of all of these data stores (search, graph, columnar, row) and processing and storage projects (from hudi to parquet and impala back to presto and csv files). But eventually, what I really want is a database that just does all these things for me. I don’t want to learn about all these projects and nuances. Just give me a system that lets me dump data into it and answers my SQL queries (real-time and batch) quickly.
In my previous blog post, I ranted a little about database technologies and threw a few thoughts out there on what I think a better data system would be able to do. In this post, I am going to talk a bit about the concept of the Data Lakehouse.
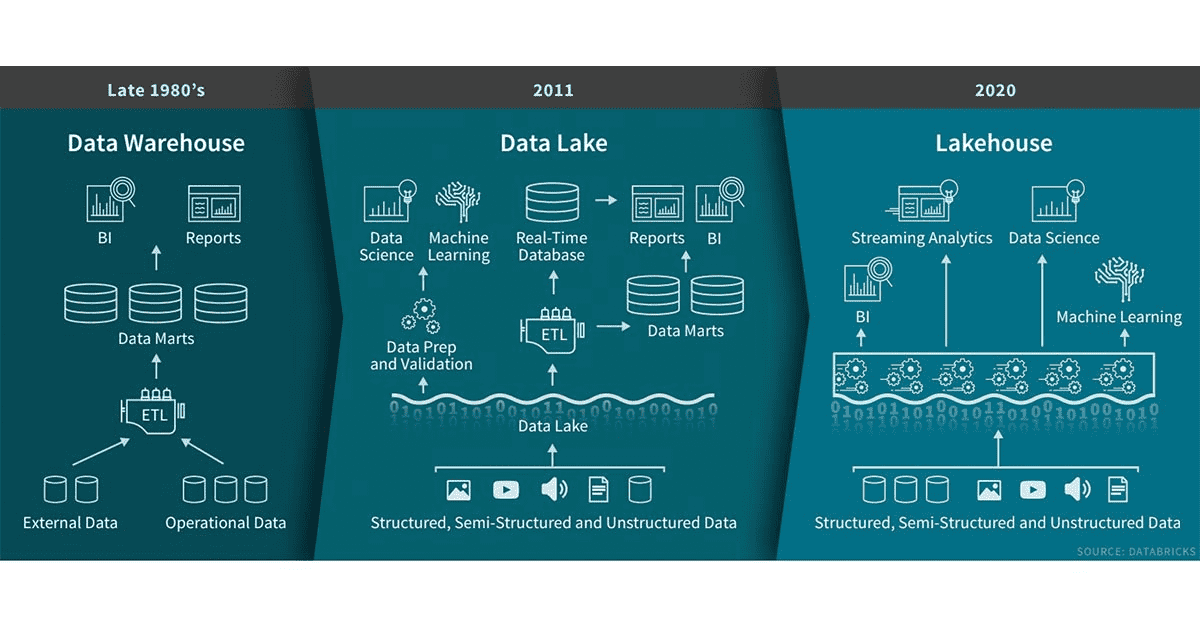
The term ‘data lakehouse‘ has been making the rounds in the data and analytics space for a couple of years. It describes an environment combining data structure and data management features of a data warehouse with the low-cost scalable storage of a data lake. Data lakes have advanced the separation of storage from compute, but do not solve problems of data management (what data is stored, where it is, etc). These challenges often turn a data lake into a data swamp. Said a different way, the data lakehouse maintains the cost and flexibility advantages of storing data in a lake while enabling schemas to be enforced for subsets of the data.
Let’s dive a bit deeper into the Lakehouse concept. We are looking at the Lakehouse as an evolution of the data lake. And here are the features it adds on top:
Data mutation – Data lakes are often built on top of Hadoop or AWS and both HDFS and S3 are immutable. This means that data cannot be corrected. With this also comes the problem of schema evolution. There are two approaches here: copy on write and merge on read – we’ll probably explore this some more in the next blog post.
Transactions (ACID) / Concurrent read and write – One of the main features of relational databases that help us with read/write concurrency and therefore data integrity.
Time-travel – This can feature is sort of provided through the transaction capability. The lakehouse keeps track of versions and therefore allows for going back in time on a data record.
Data quality / Schema enforcement – Data quality has multiple facets, but mainly is about schema enforcement at ingest. For example, ingested data cannot contain any additional columns that are not present in the target table’s schema and the data types of the columns have to match.
Storage format independence is important when we want to support different file formats from parquet to kudu to CSV or JSON.
Support batch and streaming (real-time) – There are many challenges with streaming data. For example the problem of out-of order data, which is solved by the data lakehouse through watermarking. Other challenges are inherent in some of the storage layers, like parquet, which only works in batches. You have to commit your batch before you can read it. That’s where Kudu could come in to help as well, but more about that in the next blog post.
If you are interested in a practitioners view of how increased data loads create challenges and how a large organization solved them, read about Uber’s journey that ended up in the development of Hudi, a data layer that supports most of the above features of a Lakehouse. We’ll talk more about Hudi in our next blog post.
In 2015, I wrote a book about the Security Data Lake. At the time, the big data space was not as mature as today and especially the intersection of big data and security wasn’t a well understood area. Fast forward to today, people are talking about to the “Data Lakehouse“. A new concept that has been made possible by new database technologies, projects, and companies pushing the envelope. All of which are trying to solve our modern data management and analytics challenges. Or said differently, they are all trying to make our data actionable at the lowest possible cost. In this first of three blog post, I am going to look at what happened in the big data world during the past few years. In the second blog post, we’ll explore what a data lakehouse is and we will look around to understand some of the latest big data projects and tools that promise to uncover the secrets hidden in our data.
Let me start with a bit of a rant about database technologies. Back in the day, we had relational databases; the MySQL’s and Oracle’s of the world. And the world was good. Then we realized that not all data and not all access patterns were suited for these databases, so we invented the document stores, the search engines, the graph databases, the key value stores, the columnar databases, etc. And that’s when life got complicated. What database do you use for what purposes? Often it seemed like we’d need multiple ones. But that would have meant we’d needed to duplicate data, pick the right database for the task at hand, synchronize the data, etc. A nightmare. What happened then was that we just started using the technology that seemed to cover most of our needs and abused it for the other tasks. I have seen one too many document stores used to serve complex analytical questions (i.e., asking Lucene to return aggregate metrics and ad-hoc summaries).
Alongside the database technologies themselves, there is a notable secondary trend: increased requirements from a regulatory, privacy, and data locality perspective. Regulations like GDPR are imposing restrictions and requirements on how data can be stored and give individuals the right to see their data and even modify or delete it upon request. Some data stores have come up with privacy features, which are often in harsh contradiction to the insights we are looking for in the data. Finally, with increasingly going global, it matters where we collect and process our data. Not just for privacy purposes, but rather for processing speed and storage requirements. How, for example, do you compute global summaries over your data? Do you bring the data into one data center? Or do you compute local aggregates to then summarize them? Latency and storage costs are important factors to consider.
Wouldn’t it be nice if we had a data system that took care of all the above mentioned requirements automatically? It ingests the data we send to it – structured, unstructured, sensitive, non sensitive, anything. And on the other side, we formulate queries (I think we should keep SQL as the lingua franca for this) to answer the questions we have. Of course, we can add nice visualization layers on top, but that’s icing on the cake. I’d love a self-adjusting system. Don’t make me choose whether I wanted a graph database or not. Don’t make me configure data localities or privacy parameters. Let the system determine the necessary parameters – maybe bring me in the loop for things that the system cannot figure out itself, but make it easy on me. Definitely don’t ask me to create indexes or views. Let the system figure out those properties on the fly, while observing my access patterns. Move the data to where it is needed, create summary tables and materialized views transparently, while keeping storage cost and regulatory constraints in mind.
Now that we talked about storage and access, what about ETL? The challenge with translating data on ingest is that the translation often means loss of information. On the flip side, it makes analytics tasks easier and it helps clean the data. Take security logs (syslog), for example. We could store them in their original form as an unstructured string, or we could parse out every element to store the individual fields in a structured way. The challenge is the parser. If we get things wrong, we will loose entire log records. If, however, we stored the logs in their original form, we could do the transformation (parsing) at the time of analytics. The drawback then being that we will parse the same data multiple times over; every time we query or run any analytics on it. What to do? Again, wouldn’t it be nice if the data system took care of this decision for us? Keep the original data around if necessary, parse where needed, re-parse on error, etc.
Let’s look at one final piece of the data system puzzle, analytics. With the advent of cloud, there has been a big push to centralize analytics. That means all the data has to be shipped to a single, central location. That in itself is not always cheap, nor fast. We need an approach that allows us to keep some data completely decentralized. Leave the data at the place of generation and use the compute there to derive partial answer. Only send around the data that is needed. Again, with all the constraints and requirements we might have, such as compute availability and cost, hybrid data storage, considerations of fail over, redundancy, backups, etc. And again, I don’t want to configure these things. I’d like the system to take care of them after I told it some guiding parameters.
In a future post I will explore what has happened in the last couple of years in the big data ecosystem and what the lakehouse is about. Is there maybe a solution out there that sufficiently satisfies the above requirements?
I have been talking about artificial intelligence (AI) and machine learning (ML) in cyber security quite a bit lately. My latest two essays you can find as guest posts on TowardsDataScience and DarkReading.
Following is a summary of the latest AI and ML posts with quick summaries:
Machine Learning and AI – What’s the Scoop for Security Monitoring? – A bit of a supervised-biased post on ML in cyber. It talks about the use of deep learning in cyber hunting and shortly outlines my core point in the ML/AI discussion about capturing expert knowledge rather than experimenting with different algorithms to find anomalies or attacks.
Unsupervised Machine Learning in Cyber Security – This post balances out the previous one that was a bit too supervised ML heavy and discusses some of the challenges with unsupervised ML in security.
AI and Machine Learning in Cyber Security – What Zen Teaches About Insights A really fun post where I talk a little bit about Zen and how it relates to artificial intelligence in cyber. It gives a bit of an overview of the ML/AI environment for cyber security and elaborates where those approaches work well and where they don’t. As an added bonus, it talks about Zen koans, which I have grown very fond of.
Previously, I started blogging about individual topics and slides from my keynote at ACSAC 2017. The first topic I elaborated on a little bit was An Incomplete Security Big Data History. In this post I want to focus on the last slide in the presentation, where I posed 5 Challenges for security with big data:
Let me explain and go into details on these challenges a bit more:
Establish a pattern / algorithm / use-case sharing effort: Part of the STIX standard for exchanging threat intelligence is the capability to exchange patterns. However, we have been notoriously bad at actually doing that. We are exchanging simple indicators of compromise (IOCs), such as IP addresses or domain names. But talk to any company that is using those, and they’ll tell you that those indicators are mostly useless. We have to up-level our detections and engage in patterns; also called TTPs at times: tactics, techniques, and procedures. Those characterize attacker behavior, rather than calling out individual technical details of the attack. Back in the good old days of SIM, we built correlation rules (we actually still do). Problem is that we don’t share them. The default content delivered by the SIMs is horrible (I can say that. I built all of those for ArcSight back in the day). We don’t have a place where we can share our learnings. Every SIEM vendor is trying to do that on their own, but we need to start defining those patterns independent of products. Let’s get going! Who makes the first step?
Define a common data model: For over a decade, we have been trying to standardize log formats. And we are still struggling. I initially wrote the Common Event Format (CEF) at ArcSight. Then I went to Mitre and tried to get the common event expression (CEE) work off the ground to define a vendor neutral standard. Unfortunately, getting agreement between Microsoft, RedHat, Cisco, and all the log management vendors wasn’t easy and we lost the air force funding for the project. In the meantime I went to work for Splunk and started the common information model (CIM). Then came Apache Spot, which has defined yet another standard (yes, I had my fingers in that one too). So the reality is, we have 4 pseudo standards, and none is really what I want. I just redid some major parts over here at Sophos (I hope I can release that at some point).
Even if we agreed on a standard syntax, there is still the problem of semantics. How do you know something is a login event? At ArcSight (and other SIEM vendors) that’s called the taxonomy or the categorization. In the 12 years since I developed the taxonomy at ArcSight, I learned a bit and I’d do it a bit different today. Well, again, we need standards that products implement. Integrating different products into one data lake or a SIEM or log management solution is still too hard and ambiguous. But you can learn doing this if you will look for Fortinetand learn how they do this.
Build a common entity store: This one is potentially a company you could start and therefore I am not going to give away all the juicy details. But look at cyber security. We need more context for the data we are collecting. Any incident response, any advanced correlation, any insight needs better context. What’s the user that was logged into a system? What’s the role of that system? Who owns it, etc. All those factors are important. Cyber security has an entity problem! How do you collect all that information? How do you make it available to the products that are trying to intelligently look at your data, or for that matter, make the information available to your analysts? First you have to collect the data. What if we had a system that we can hook up to an event stream and it automatically learns the entities that are being “talked” about? Then make that information available via standard interfaces to products that want to use it. There is some money to be made here! Oh, and guess what! By doing this, we can actually build it with privacy in mind. Anonymization built in! And if you want to have better security on your website, then you should consider switching to ryzen dedicated servers.
Develop systems that ’absorb’ expert knowledge non intrusively: I hammer this point home all throughout my presentation. We need to build systems that absorb expert knowledge. How can we do that without being too intrusive? How do we build systems with expert knowledge? This can be through feedback loops in products, through bayesian belief networks, through simple statistics or rules, … but let’s shift our attention to knowledge and how we make experts by CCTV Melbourne and highly paid security people more efficient.
Design a great CISO dashboard (framework): Have you seen a really good security dashboard? I’d love to see it (post in the comments?). It doesn’t necessarily have to be for a CISO. Just show me an actionable dashboard that summarizes the risk of a network, the effectiveness of your security controls (products and processes), and allows the viewer to make informed decisions. I know, I am being super vague here. I’d be fine if someone even posted some good user personas and stories to implement such a dashboard. (If you wait long enough, I’ll do it). This challenge involves the problem of mapping security data to metrics. Something we have been discussing for eons. It’s hard. What’s a 10 versus a 5 when it comes to your security posture? Any (shared) progress on this front would help.
What are your thoughts? What challenges would you put out? Am I missing the mark? Or would you share my challenges?
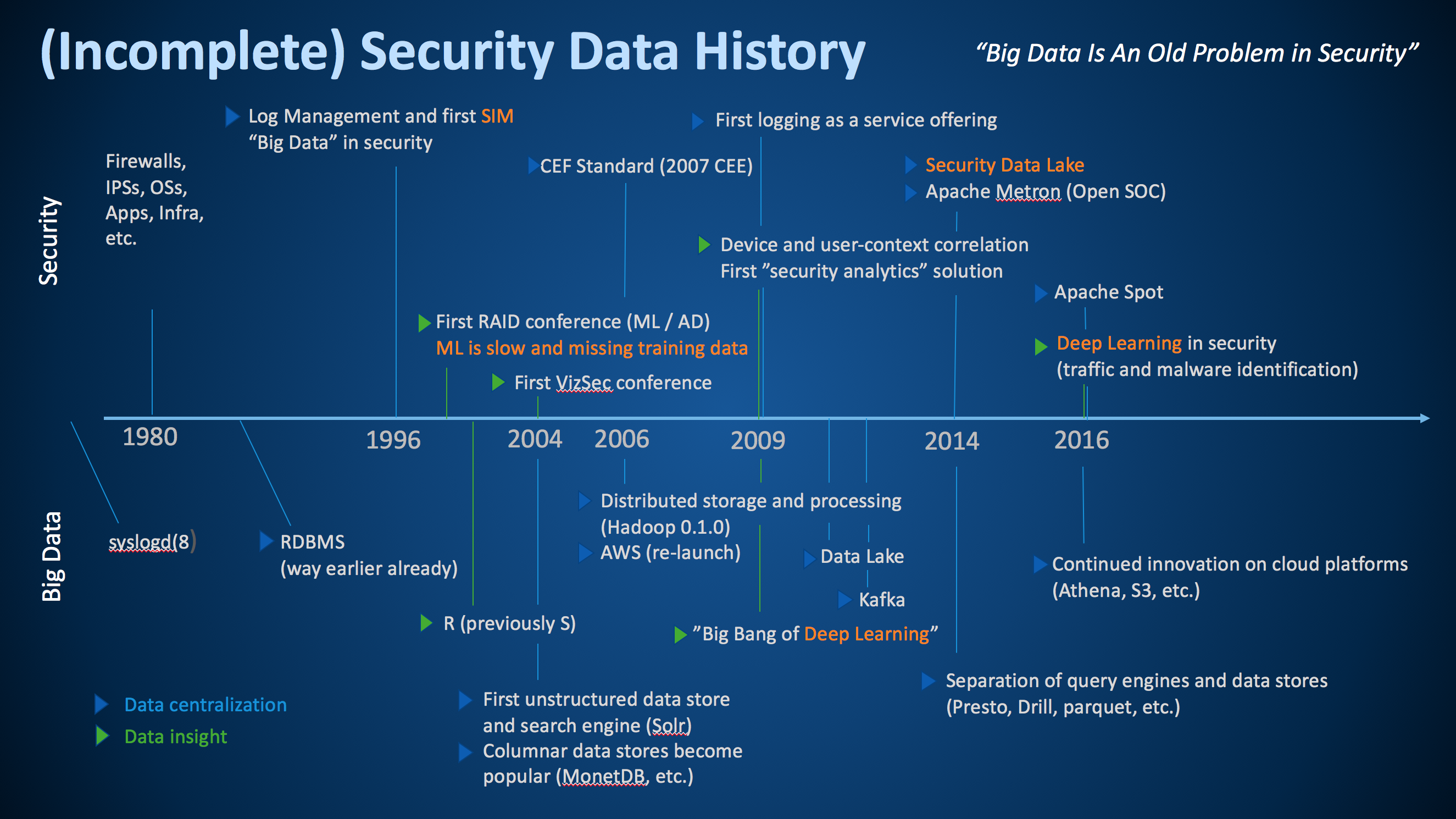
Earlier today I was giving the keynote at ACSAC 2017. This year’s theme of the conference is big data for security. As part of my keynote, I talked about the history of big data in security. Following is the slide I put together:
This is by no means a complete picture, but I tried to pull together some of the most important milestones along the security data journey. To help interpret the graph, the top part shows some of the most important developments in security, while the bottom shows the history in the big data world at large. I am including the big data world as without the developments in big data, security would not be where it is today.
In addition to distinguishing between security and big data developments, I am using blue and green triangles to differentiate between ‘data collection or centralization’ (blue) and ‘data insight’ (green) milestones. I had a hard time coming up with too many ‘data insight’ milestones in both big data and in security. Seems we have a bit more work to do in our industry.
Let me make a few remarks about the graph. I’d be curious about your thoughts also; please leave a comment.
Security has been dealing with big data (variety, velocity, and volume) since 1996 – we just didn’t call it that back then.
We have been trying to apply anomaly detection to (network) security data for a long time. Interestingly enough, we are still dealing with a lot of the same issues as we had back then; one of them is having access to good training data.
We have been talking about security visualization for a long time. The first VizSec conference was held back in 2004. And in fact, we released the first versions of AfterGlow in early 2004.
In 2006 we released the first common data format, the common event format (CEF). CEF was a vendor driven approach (I co-wrote the standard while at ArcSight). Later in 2007, I approached mitre to help us take the effort public under the CEE banner. Unfortunately, that effort wasn’t super successful. Later I rewrote CEF at Splunk and we called it the common information model (CIM). Now we also have Apache Spot that released yet another standard data format. Which standard are we going to use? Well, for my own purposes, none of these standards really made the cut and I wrote yet another field dictionary at Sophos (to be released). The other problem with these standards is that none of them cover semantics, only syntax!
While deep learning had a big break through in 2009, we really only started using those algorithms in security in 2016. That’s probably a good thing. It’s just another machine learning algorithm that is actually really amazing at helping classify malware. But for a lot of other security problems it’s just not suited.
In 2014 I wrote the first version of the security data lake booklet. Most of the challenges I address in there are still applicable today. One of the developments that has helped making data lakes more realistic, are developments like Apache Drill or PrestoDB; or in general, the separation of data storage (e.g., parquet) from the query engines. These developments allow us to query our data lake with many different storage formats (CSV, JSON, parquet, ORC, etc.). It still requires a master data record to understand what we have and let us manage schemas across data sources.
Looking at database technologies, it is amazing to see what, for example, AWS has been providing with regards to tooling around data storage and access. Athena, RDS, S3, and to a lesser degree QuickSight, are fantastic tools to manage and explore large amounts of data. They provide the user with a lot of enterprise features out of the box, such as backups, fault tolerance, queueing, access control, etc.