After my latest blog post on “Machine Learning and AI – What’s the Scoop for Security Monitoring?“, there was a quick discussion on twitter and Shomiron made a good point that in my post I solely focused on supervised machine learning.
In simple terms, as mentioned in the previous blog post, supervised machine learning is about learning with a training data set. In contrast, unsupervised machine learning is about finding or describing hidden structures in data. If you have heard of clustering algorithms, they are one of the main groups of algorithms in unsupervised machine learning (the other being association rule learning).
There are some quite technical problems with applying clustering to cyber security data. I won’t go into details for now. The problems are related to defining distance functions and the fact that most, if not all, clustering algorithms have been built around numerical and not categorical data. Turns out, in cyber security, we mostly deal with categorical data (urls, usernames, IPs, ports, etc.). But outside of these mathematical problems, there are other problems you face with clustering algorithms. Have a look at this visualization of clusters that I created from some network traffic:
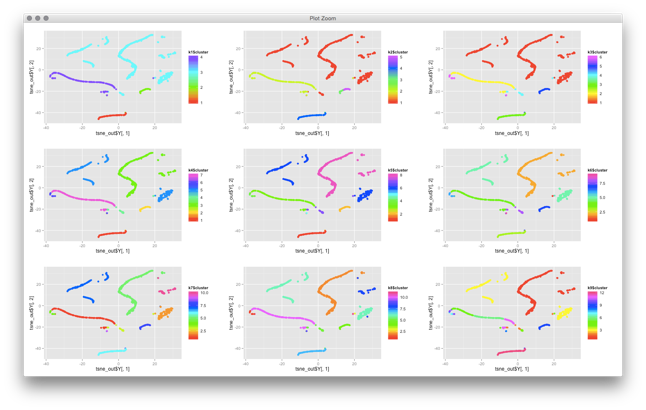
Some of the network traffic clusters incredibly well. But now what? What does this all show us? You can basically do two things with this:
- You can try to identify what each of these clusters represent. But the explainability of clusters is not built into clustering algorithms! You don’t know why something shows up on the top right, do you? You have to somehow figure out what this traffic is. You could run some automatic feature extraction or figure out what the common features are, but that’s generall not very easy. It’s not like email traffic will nicely cluster on the top right and Web traffic on the bottom right.
- You may use this snapshot as a baseline. In fact, in the graph you see individual machines. They cluster based on their similarity of network traffic seen (with given distance functions!). If you re-run the same algorithm at a later point in time, you could try to see which machines still cluster together and which ones do not. Sort of using multiple cluster snapshots as anomaly detectors. But note also that these visualizations are generally not ‘stable’. What was on top right might end up on the bottom left when you run the algorithm again. Not making your analysis any easier.
If you are trying to implement case number one above, you can make it a bit little less generic. You can try to inject some a priori knowledge about what you are looking for. For example, BotMiner / BotHunter uses an approach to separate botnet traffic from regular activity.
These are some of my thoughts on unsupervised machine learning in security. What are your use-cases for unsupervised machine learning in security?
PS: If you are doing work on clustering, have a look at t-SNE. It’s a clustering algorithm that does a multi-dimensional projection of your data into the 2-dimensional space. I have gotten incredible results with it. I’d love to hear from you if you have used the algorithm.
The other day I presented a Webinar on Big Data and SIEM for IANS research. One of the topics I briefly touched upon was machine learning and artificial intelligence, which resulted in a couple of questions after the Webinar was over. I wanted to pass along my answers here:
Q: Hi, one of the biggest challenges we have is that we have all the data and logs as part of SIEM, but how to effectively and timely review it – distinguishing ‘information’ from ‘noise’. Is Artificial Intelligence (AI) is the answer for it?
A: AI is an overloaded term. When people talk about AI, they really mean machine learning. Let’s therefore have a look at machine learning (ML). For ML you need sample data; labeled data, which means that you need a data set where you already classified things into “information” and “noise”. Form that, machine learning will learn the characteristics of ‘noisy’ stuff. The problem is getting a good, labeled data set; which is almost impossible. Given that, what else could help? Well, we need a way to characterize or capture the knowledge of experts. That is quite hard and many companies have tried. There is a company, “Respond Software”, which developed a method to run domain experts through a set of scenarios that they have to ‘rate’. Based on that input, they then build a statistical model which distinguishes ‘information’ from ‘noise’. Coming back to the original question, there are methods and algorithms out there, but the thing to look for are systems that capture expert knowledge in a ‘scalable’ way; in a way that generalizes knowledge and doesn’t require constant re-learning.
Q: Can SIEMs create and maintain baselines using historical logs to help detect statistical anomalies against the baseline?
A: The hardest part about anomalies is that you have to first define what ‘normal’ is. A SIEM can help build up a statistical baseline. In ArcSight, for example, that’s called a moving average data monitor. However, a statistical outlier is not always a security problem. Just because I suddenly download a large file doesn’t mean I am compromised. The question then becomes, how do you separate my ‘download’ from a malicious download? You could show all statistical outliers to an analyst, but that’s a lot of false positives they’d have to deal with. If you can find a way to combine additional signals with those statistical indicators, that could be a good approach. Or combine multiple statistical signals. Be prepared for a decent amount of caring and feeding of such a system though! These indicators change over time.
Q: Have you seen any successful applications of Deep Learning in UEBA/Hunting?
A: I have not. Deep learning is just a modern machine learning algorithm that suffers from all most of the problems that machine learning suffers from as well. To start with, you need large amounts of training data. Deep learning, just like any other machine learning algorithm, also suffers from explainability. Meaning that the algorithm might classify something as bad, but you will never know why it did that. If you can’t explain a detection, how do you verify it? Or how do you make sure it’s a true positive?
Hunting requires people. Focus on enabling hunters. Focus on tools that automate as much as possible in the hunting process. Giving hunters as much context as possible, fast data access, fast analytics, etc. You are trying to make the hunters’ jobs easier. This is easier said than done. Such tools don’t really exist out of the box. To get a start though, don’t boil the ocean. You don’t even need a fully staffed hunting team. Have each analyst spend an afternoon a week on hunting. Let them explore your environment. Let them dig into the logs and events. Let them follow up on hunches they have. You will find a ton of misconfigurations in the beginning and the analysts will come up with many more questions than answers, but you will find that through all the exploratory work, you get smarter about your infrastructure. You get better at documenting processes and findings, the analysts will probably automate a bunch of things, and not to forget: this is fun. Your analysts will come to work re-energized and excited about what they do.
Q: What are some of the best tools used for tying the endpoint products into SIEMs?
A: On Windows I can recommend using sysmon as a data source. On Linux it’s a bit harder, but there are tools that can hook into the audit capability or in newer kernels, eBPF is a great facility to tap into.
If you have an existing endpoint product, you have to work with the vendor to make sure they have some kind of a central console that manages all the endpoints. You want to integrate with that central console to forward the event data from there to your SIEM. You do not want to get into the game of gathering endpoint data directly. The amount of work required can be quite significant. How, for example, do you make sure that you are getting data from all endpoints? What if an endpoint goes offline? How do you track that?
When you are integrating the data, it also matters how you correlate the data to your network data and what correlations you set up around your endpoint data. Work with your endpoint teams to brainstorm around use-cases and leverage a ‘hunting’ approach to explore the data to learn the baseline and then set up triggers from there.
Update: Check out my blog post on Unsupervised machine learning as a follow up to this post.
