RSAC 2026 made one thing very clear to me: the market is moving fast, but it is still deeply confused. The big announcements from Google, Splunk, and Databricks all point in the same direction. Security operations are becoming more agentic, more API-driven, and more automated. But most of the category still looks crowded, early, and only lightly differentiated.
The interesting part is not that everybody now has an AI story. It is where the pressure is landing: attack speed, active response, and the possibility that AI itself becomes the primary user of the security stack.
TL;DR
Attacks are now fast enough that human-speed response is no longer a sufficient default.
That will push the market toward active response, which is useful but also dangerous if the control logic is not deterministic enough.
Most AI SOC vendors still sound similar because many of them sit on top of existing SIEMs and alert streams rather than changing the underlying detection or data architecture.
The big SIEM vendors are moving, and one major EDR/SIEM vendor is expanding AI security into on-prem and sovereign environments.
If AI becomes the user of security products, the UI matters less, the API matters more, and the economics of expensive SIEM platforms get harder to defend.
Attacks are getting faster
This is the part of the market I think people are still underestimating. CrowdStrike’s 2026 threat report says the average eCrime breakout time dropped to 29 minutes in 2025, and the fastest case it observed was 27 seconds. Databricks used its Lakewatch announcement to make a related point from the vulnerability side, citing research that mean time to exploit has fallen from 23.2 days in 2025 to 1.6 days in 2026.
That changes what matters in the SOC. A lot of SIEM workflows still assume there is time to search, enrich, discuss, and decide. That model was already strained. It gets worse when attacks speed up and when the adversary is using AI to compress its own loop. Search still matters, but a search-centric operating model is not enough if the environment can be compromised end to end in under an hour.
The obvious answer is more active response. The problem is that this is where things get dangerous. If teams start handing more containment and remediation decisions to AI before the systems are ready, we are going to see more self-inflicted outages. The market is moving there anyway, because the alternative is to keep defending at human speed against machine-speed attacks. SOAR was supposed to close part of that gap and clearly did not.
AI SOC is still confusing and mostly sounds the same
That was probably my main emotional reaction leaving RSAC: confusion. There were simply too many vendors with very similar messaging. RSAC says the conference had more than 600 exhibitors this year. I could not independently validate an exact count of 36 AI SOC vendors from public RSAC data, but “roughly three dozen” felt directionally right from the floor, and many of them sounded remarkably similar.
The common pitch was familiar: reduce alerts, triage faster, investigate faster, give the analyst a copilot, automate parts of response. Some of that is clearly useful. But a lot of it still feels like a layer on top of the existing SIEM rather than a rethink of the detection stack itself. If the AI mostly sits on top of alert streams coming out of a legacy backend, then it may improve analyst productivity without materially fixing false negatives, brittle detections, or poor data design upstream.
That is also why I do not think most of this market is really using LLMs in a deep way yet. In most cases, the models are being used for triage, recommendations, summarization, and analyst assistance. That is very different from using LLMs for real detection, broader SOC operations, or meaningful changes to the underlying architecture.
That is why so much of the category feels undifferentiated. The interfaces are different, the branding is different, and the demo flows are different, but the center of gravity often looks the same. The latest platform announcements only reinforce that point. If the platform owner adds the agentic layer too, the vendors sitting on top of Chronicle, Splunk, or similar platforms have a much harder moat to defend.
The architecture is shifting
By this point, the vendor movement is established. The more interesting question now is what it does to architecture. SentinelOne adds another signal here by pushing more AI security capability into on-prem, sovereign, and air-gapped environments.
Put together, that points to a broader market shift. Storage matters more. Data routing matters more. Sovereignty and local control matter more. Cheap data lakes, strong analytics layers, and flexible orchestration matter more. Traditional SIEM UI matters less than it used to, and that matters not just for SIEM vendors but also for MDRs that differentiated by putting an AI layer on top of someone else’s backend.
That is also why Splunk’s cost model keeps coming back into the conversation. Splunk is powerful and mature, but if the agent becomes the main consumer of the system, customers start asking a different question: am I paying for the analytics engine, or am I paying for UI, workflow, and operating complexity that an agent increasingly does not care about?
If AI becomes the user, the stack changes
The most important implication may be economic, not just operational. Security products were built for human analysts. The value lived in the UI, the workflow, the search language, the dashboard, and the services needed to make all of that usable. But what happens if the real user becomes Claude Code, Codex, Gemini, or some internal agent instrumented across the entire security stack? Daniel Miessler has been arguing that companies and products increasingly become APIs. Security looks like one of the clearest versions of that shift.
In that world, every product starts to look more like an API than an application. That is exactly where the recent announcements are heading. LimaCharlie’s new lc-soc release is a concrete implementation of the same idea: an open-source “agentic SOC as code” where AI agents are coordinated through the cases system and D&R rules, then deployed and versioned like infrastructure.
If AI becomes the primary user, the UI does not disappear, but it stops being the center of gravity. The agent does not care about your console. It cares about whether the data is accessible, whether the schema is consistent, whether the analytics layer is fast, whether the permissions model is clean, and whether the actions are safe to orchestrate.
That creates real pressure on expensive SIEM economics. If the agent can query multiple tools directly, the premium attached to a deeply monetized UI gets harder to justify. The market may move toward something simpler: cheap storage, a strong analytics layer, and an orchestration layer on top. That does not mean incumbents disappear. It means their value proposition changes. If AI becomes the user, the winners may be the vendors with the best APIs, control points, and data access model.
Evals become part of the control layer
The next problem is trust and determinism. Once you push AI beyond triage and recommendations and let it make or recommend more consequential changes, you need a way to keep the system reliable. That is where eval loops come in.
I heard Josh Saxe make this point at RSAC in the context of AI-first infrastructure management: if agents are going to make changes in live systems, you need strong evaluation around them to keep behavior bounded and repeatable enough to trust. I think the same logic applies directly to security operations. The market is moving toward active response, but the models themselves were not built around strict determinism.
That means the answer is not blind autonomy. It is more likely a layered system where adaptive AI sits inside clearer control boundaries, with evals, policy, and deterministic automation around it. Evals stop being an AI engineering detail and become part of the security control layer itself.
I recently joined Tim Peacock and Anton Chuvakin on the Google Cloud Security Podcast to talk about SIEM, AI SOC, pricing, federated architecture, detection engineering, and why network telemetry is quietly becoming important again.
The short version is simple: SIEM is not dead. Calling it obsolete makes for good marketing, but it is not a serious thesis.
The new wave of AI SOC, SIEM, and pipeline vendors is not proving SIEM is dead. It is proving SIEM vendors left too many gaps open for too long.
The recent wave of AI SOC startups, pipeline vendors, and new SIEM entrants is a response to real pain in the market. They are not replacing SIEM. They are capitalizing on the gaps incumbent vendors left open.
TL;DR
SIEM is not dead. Vendors just left too many gaps open.
AI SOC often exposes those gaps more than it replaces SIEM.
Alert reduction alone will hide false negatives.
The real fixes are better routing, detection, context, and workflows.
Network telemetry still matters more than the market narrative suggests.
The market is not replacing SIEM. It is rebuilding missing pieces.
They say they will reduce alert volume, improve detections, make investigations faster, lower storage costs, and simplify operations. None of that is new. Those were always core parts of the SIEM vision.
That is why so many of these new entrants exist. They found real gaps:
Pricing that became too hard to justify
Architectures that did not scale as well as they should
Detection stacks that still require too much manual work
Default content that creates too much noise
Workflows that remain painful for analysts and service providers
This is why I do not buy the “SIEM is over” narrative. If incumbents fix these gaps, many point solutions lose their edge quickly.
AI SOC is mostly a patch on downstream pain
The strongest short-term value in the AI SOC market is obvious: too many teams, especially MSSPs and down-market security providers, are drowning in alerts. A lot of environments are running with default content, light tuning, and limited budget for customization. Large enterprises can afford deep implementation and constant refinement. Many managed providers cannot.
If a product makes the SOC quieter without improving coverage, you may not have solved the problem. You may have just converted visible false positives into invisible false negatives.
If a startup is solving alert overload by learning that the same service-account misconfiguration fires every morning at 8am and can safely be deprioritized, that is useful. But it is still a patch on bad upstream logic, and it often hides a second problem: false negatives. Once teams see fewer alerts, they assume the system got smarter. Sometimes it did. Sometimes it just got quieter. The real fix belongs closer to the detection layer, the correlation logic, the content, and the configuration model.
That is why I think a lot of the current AI SOC wave is temporary in its present form. Not temporary because the need goes away, but temporary because the best parts of that value will be absorbed elsewhere. Some of it should move back into the SIEM. Some of it should live in the detection engine. Some of it belongs in better onboarding, better rule tuning, better data handling, and better defaults.
There is still room for new winners here. But “we reduce alerts by 80%” is not a durable thesis by itself.
The architecture debate is not centralized versus federated. It is about access patterns.
In theory, pushing compute to where the data sits is attractive. In practice, the answer depends on access patterns.
Some data absolutely does not need to be centralized all the time. Endpoint system calls are a good example. You do not want to shovel every low-level signal into a central platform by default if you can process, summarize, or prioritize it earlier.
But the moment an analyst, agent, or investigation workflow needs context, enrichment, and cross-correlation, some centralization comes back. You need to connect what happened on the endpoint with what happened on the firewall, identity plane, SaaS layer, email stack, and elsewhere.
So the future is probably not pure centralized or pure federated. It is hybrid:
Keep some data local or near-source
Route and centralize the parts that matter
Pull deeper context only when needed
Optimize around how investigations actually happen
This is why I keep coming back to smart data routing. Most organizations do not need to send every piece of data to the same place forever. But they do need an architecture that knows when to summarize, when to correlate, and when to pull more detail back in.
Data pipelines became the Trojan horse
Vendors in this space positioned themselves as optimization and routing tools. Send your data here, normalize it, trim low-value volume, route it to the right storage tier, keep costs down, and retain optionality. In many environments, that solved a real problem.
Once a pipeline vendor owns your ingestion layer and your integrations, it becomes an abstraction layer between you and the SIEM. That makes the SIEM less sticky. At first the pipeline vendor only routes data. Then it adds search. Then it runs lightweight detections. Then it supports simple rules. At some point it starts to look suspiciously like a simple SIEM.
If someone else owns the data path, they eventually get a shot at owning more of the security brain.
Pricing remains one of the category’s hardest unsolved problems
Almost everyone agrees that SIEM pricing has been a problem. Much fewer people agree on what the right answer is.
The vendor reality is straightforward: data volume drives cost. The customer reality is equally straightforward: they hate unpredictability.
That tension gets even worse in the service-provider world. MSSPs and MSPs often sell packaged services, per-user offerings, or per-device contracts. Their customers do not want a fluctuating bill because log volume spiked this month. So the thing that is economically clean for the vendor can be operationally ugly for the buyer.
There is no perfect answer here. But the next generation of pricing models will need to do a better job of separating:
Predictable commercial packaging
Actual backend resource consumption
Incentives for better data quality rather than more raw ingestion
The market has already started experimenting. Bring-your-own-storage, bring-your-own-compute, lower-cost data lakes, and more selective routing are all responses to the same pressure. Pricing is one of the core forces reshaping the market.
Detection engineering still needs much more help from the platform
Rules still need adaptation by environment. Thresholds differ. Data quality differs. Sources differ. Customer expectations differ. Generic content does not simply drop in and work.
What is surprising is how much low-hanging product work still remains. A modern platform should do far more to help users answer basic but critical questions:
Is the data required for this detection even present?
Is it configured in a way that can ever make this rule fire?
Are there obvious gaps or mistakes in the source configuration?
Which detections are silent because they are poorly mapped to the environment?
The more interesting direction, in my view, is not just better standalone rules. It is better context. Call it a context graph, an entity graph, a risk graph, or something else. The naming matters less than the function.
You want a living model of users, devices, applications, identities, behaviors, and risk signals. If the system knows that a user is coming from their normal IP, on a familiar device, through a known browser pattern, after strong authentication, that should shape how other events are interpreted. If all of those signals change at once, that should shape the response differently.
That kind of context is where detection quality meaningfully improves.
Network telemetry is not “back,” but it is still critical
I do not think this automatically means a major standalone NDR renaissance. But I do think many teams went too far in treating network telemetry as secondary once endpoint and application visibility improved.
An endpoint is still a single point of failure. If you lose visibility there, the network can still tell you a lot. It can help validate what else is happening. It can show you unmanaged systems, OT environments, choke points, and traffic patterns you will not otherwise see clearly.
This matters even more now because some organizations are reassessing where systems and data live. In parts of Europe, I am seeing more discussion around data sovereignty, political trust, private clouds, and selective moves back toward local or regional infrastructure. As architectures spread and governance constraints tighten, network visibility becomes more important again.
So no, I would not frame this as “throw away EDR and buy NDR.” That is the wrong lesson.
What happens next
The real question is not whether SIEM survives. It is which vendors understand they are now selling data architecture, detection quality, analyst workflow, and decision support.
The SIEM market is heading into another rebuild cycle. Some AI SOC and pipeline startups will disappear, some will be absorbed, and some incumbents will finally fix what they should have fixed years ago. But the core need is not going away: security teams still need a place where signals come together, context gets built, detections improve, and response decisions get made.
That is still SIEM territory, even if the implementation looks very different from what we used to buy.
? If you are building, buying, operating, or replacing SIEM, I’d love your input. I’m collecting market data at raffy.ch/SIEM. Anyone can contribute, and everyone is welcome.
Update: Instead of an Excel spreadsheet, here is an online app that you can use. I’d love for you to submit your own ratings so we can crowd-source some of these answers!
“Ok, but how do I evaluate vendors consistently without falling back into feature checklists and marketing claims?”
So I turned the framework into a practical scoring workbook (and now a small Web application) you can use to rate a platform across the dimensions I described in the post. The workbook allows you to rate each category from 1 to 5 and I spent some time defining what a 1 versus a 5 means in each of the categories. I give you an example for the “Data Pipeline Optimization” category. Here are the 5 maturity steps:
1 | Static ingestion pipelines that forward all data to a central store.
2 | Basic filtering or routing based on source or log type.
3 | Conditional enrichment and routing based on use case or predefined alerts/rules.
4 | Dynamic pipelines that adapt sampling, enrichment, and routing based on downstream value.
5 | Continuously optimized pipelines driven by feedback loops from detections, cost, and analyst outcomes.
I hope the breakdown into these 5 values helps going through a more ‘objective’ assessment of these platforms and also shows what excellent looks like in each of these categories.
What this is
The Security Analytics Platforms – Maturity Framework is an architecture-first tool to evaluate security platforms across architectural, detection, and operational dimensions. It is designed to help you compare systems based on their advanced capabilities that are desperately needed to deliver a SIEM experience that is adequate for 2026..
What this is not
This is not a vendor ranking, a feature checklist, or a replacement for hands-on testing. It’s also NOT an RFP template. As I indicated in my previous blog where I outlined all the different categories, the table stakes are not mentioned or evaluated.
How to use it in 10 minutes
Add one vendor per row in the rating sheet.
Score each topic based on current behavior, not roadmap promises.
Review category roll-ups and the heatmap to spot structural gaps.
A key insight: large gaps between category scores often matter more than the overall score.
Security analytics is in the middle of a reset. Incumbent SIEMs are being re-architected, new SIEM startups are emerging, and AI SOC vendors are rewriting parts of the operating model. End users and investors need a way to evaluate these platforms objectively, beyond feature checklists and marketing claims. This workbook is my attempt to make that evaluation repeatable, comparable, and anchored in the areas that I see missing or deficient in the incumbent SIEM space.
If you use it, I’d love your feedback
If you score a platform with it, use the Web app and submit your rating. You need to log in via Github or Google so I don’t get flooded with fake entries. I’d love to crowdsource an assessment of all the SIEM and AI SOC vendors out there. Can we do it?
I have been talking to a few AI SOC and new SIEM market entrants over the past few weeks. I have voiced some opinions in previous posts but have now started to capture a list of features that I believe represent the openings existing SIEM players have created in the market for these new vendors to emerge.
Before I outline what I think those features are, let me be clear: this is my list. I am aware that existing SIEM vendors will claim that they already do many of these things. All I will say is this: market churn and capital flow suggest that these capabilities are either not as mature or not as integrated as claimed.
And to the AI SOC companies and investors: be careful about the short-term problems your investments are solving. Yes, there is real traction with MSSPs that are overloaded with false positives. And yes, many will gladly pay to reduce alert workload by 80%. But in many cases, these problems are being addressed superficially. Make sure you audit the underlying approaches and verify that the foundational infrastructure is sound. Solving this problem on top of an existing detection infrastructure doesn’t solve the problem at the core, which is the detections themselves. We need to fix those with some of the suggestions below to not needing a top-layer, alert reducer.
Without further ado, here are the items I am tracking. I welcome other opinions and additions to the list (no guarantee I will include them). Over the coming weeks, I will also try to rate some of the players across these categories to enable comparison. I could use help with that. Ping me.
A. DATA & CONTROL PLANE ARCHITECTURE
Federation – The ability to query and reason over data where it lives, without forced centralization. (Another post following here at some point about the limitations of federation).
Data PipelineOptimization – Dynamic ingestion pipelines that enrich, route, sample, and filter data based on use case, risk, and downstream value. Not static “send everything to the lake.”
Data Awareness – Understanding what data exists, what is missing, and what has silently degraded. The system must continuously reason about its own observability.
Performance as a First-Class Constraint – Fast joins and low-latency queries across all relevant data. Real-time rule execution at scale. This is not about basic scalability, but about maintaining predictable performance as rule count and complexity increase, without simply throwing more compute at the problem.
Modern AI Integration – The ability to integrate with emerging architectural patterns and frameworks, including MCP servers, vector stores, and related systems.
B. DETECTION & LEARNING SYSTEMS
Hypothesis-Driven Hunting – Hunting should start with explicit hypotheses, not ad-hoc queries. These hypotheses should evolve, fork, and self-update based on outcomes. Agents swarms anyone?
Automated Detection Tuning (Closed Loop) – Detections must evaluate their precision and recall over time. False positives and false negatives are signals. Humans stay in the loop, but are not the tuning engine. This also helps separate the detection engineering from the tuning that should be done by analysts.
Environment-Adaptive Detections – Rules and models must adapt automatically to the specific environment, business processes, and user behavior and analyst feedback. Generic detections are table stakes.
Detection Lineage and Memory – The system must remember why a detection exists, how it has changed, and what outcomes it has historically produced.
C. ENTITY-CENTRIC RISK & CONTEXT
Asset Awareness – Effective protection and detection start with understanding what is being protected. Entity visibility is foundational: who owns this entity, what does it do, and which business processes does it support?
Real-Time Entity Risk Scoring – Each entity has a continuously updated risk score driven by behavior, exposure, and contextual signals.
Entity Risk Context – Risk is not a number. It is a set of properties that help explain the risk and provide context for decision making.
Business Context Integration – Entities must be tied to business processes, ownership, and criticality, and this context must inform alert generation and prioritization. Some people have started calling this the Context Graph.
D. OPERATIONAL REALITY (SOC, MSSP, ENFORCEMENT)
Simple QueryInterface: Support for both natural language and structured query languages (such as KQL). Analysts need both.
Alert Triage Automation – Using ‘advanced’ context to tune detections. Ideally we have business context available to continuously improve our detections.
Blindspot Detection – The system must actively identify where detections cannot exist due to missing or degraded logs or logging configurations. This includes making sure that log sources are actually staying up and keep reporting what they have to.
Real-Time Readiness for Enforcement – We need our systems to become preventative. Therefore, its risk model must operate in near real time. Attackers are acting too fast.
A Few Additional Comments for Context
This is not meant to be a SIEM RFP. I am intentionally not listing table-stakes capabilities such as basic scalability, data source support, or baseline detection depth.
This list is less about features than about where intelligence and control actually live in the system. I am also not being prescriptive on how these features are built. Many of them can benefit from AI / LLM / ML approaches and, in fact, should be using them.
Look at the list, then look at your AI SOC platform of choice. How much of the above does it truly cover?
If you are evaluating an AI SOC platform and most of its value proposition lives above alerts rather than below them, you should be skeptical.
Security has always moved in waves. Not because we suddenly get smarter, but because we learn from past mistakes, identify gaps, hit limits, need to protect new technologies, and then go and do our best to solve those new security challenges with the technologies at hand.
The era of AI (let’s be clear, we have had AI for a long time; what I mean specifically is the advent of Large Language Models) has shifted many industries, but specifically security in a particularly revealing way. AI did not just give us new tools to solve security problems. It invited innovators and entrepreneurs to revisit pretty much every security technology to see if LLMs could be useful to address some of the existing challenges. But that’s not where things stopped. More interestingly, some teams used this moment to question whether the underlying approaches themselves still made sense at all. Not just whether LLMs could help, but whether modern data architectures, different telemetry choices, and different enforcement models could fundamentally change outcomes.
That is what has triggered a real wave of new companies in cyber, including across markets that many considered mature, or even stagnant, like SIEM.
The Five Phases We Just Lived Through
Let’s take a non-scientific look at how major security approaches evolved over the past 25 years. This is not exhaustive, but it helps explain where we are today.
1. Network-Centric Prevention
Back, many moons ago, we started with firewalls, IDS, and later IPS. The model was simple. Look at packets. Stop bad things. It worked until attackers learned to look normal.
2. More Data, Centralized, Higher-Level Insights
When network telemetry created too many false positives, we added vulnerability data and authentication events and fed them into a SIEM to correlate. The results were “mixed”. Fortunately for the SIEM market, compliance and audit requirements emerged, mandating long-term log retention. This gave SIEM a durable justification, even when its security value was debated. SIEM became indispensable for visibility and forensics, but increasingly disconnected from real-time decision making.
3. Back to Prevention and Response
As SIEM alert volumes exploded and analysts could not keep up, the industry pivoted. EDR. NDR. SOAR. We all know how that played out. NDR never truly broke out. EDR became a major category. SOAR largely collapsed back into SIEM. And eventually, most large EDR vendors added a SIEM to their portfolio.
This was not convergence by design. It was convergence driven by operational gravity.
4. AI Triggers a Reality Check
LLMs made many believe they could simply layer AI on top of broken architectures. Some startups did exactly that. They will likely not be the long-term winners.
The more interesting group of companies used AI as a forcing function to re-examine first principles. What data actually matters? What can realistically be prevented at the edge? What must still be correlated centrally? What is structurally broken in SOC workflows? Where have we been compensating for bad architecture with human labor? Crucially, many of these answers have little to do with LLMs themselves, and much more to do with data fidelity, placement of control, and modern system design. This is where the real innovation is happening.
5. The Convergence
We are now in a phase where prevention is moving back to the edge, while analytics and orchestration remain central. Endpoints are smarter. Browsers are instrumented. Networks are being re-observed. Context is finally treated as a first-class input.
But there is still a SOC. There is still a central nervous system that correlates, reconstructs, explains, orchestrates, and proves what happened. Call it SIEM, security analytics, XDR, or AI SOC. The name is irrelevant. The function is not.
In parallel, we are realizing that we can push enforcement / prevention back to the edge. Wherever we have enough information, execute at the edge. Where we don’t, call out to your central nervous system. To your brain. The brain (your SIEM) that understands at any moment in time, what the risk and function is of every entity in your network. And use that information for decision making.
Why AI SOC Will Collapse Back Into SIEM
Many startups brand themselves as “AI SOC”. What do they actually do?
They primarily ingest alerts from EDR, NDR, SIEMs, and cloud platforms, then attempt to determine which ones matter. They add context, apply behavioral analysis, and suppress false positives.
In other words, they attempt to do what SIEM, UEBA, and SOAR were always supposed to do, just with better math and more compute. However, there is one problem. Many of the AI SOC contenders operate on alert streams. That means they start from already lossy, opinionated data. Real behavioral analysis does not on top of alert streams. It lives in raw telemetry. Email flows. Network sessions. Browser actions. Endpoint system behavior.
Once an AI SOC platform decides to ingest that raw data directly, it immediately recreates the ingestion, normalization, storage, and correlation problems that SIEM already exists to solve. At that point, the separation no longer makes sense. This is exactly why UEBA and SOAR collapsed back into SIEM. And it is why AI SOC will do the same.
There will be one place where data is reconciled, correlated, and turned into decisions. That place will increasingly run on federated, near-real-time architectures rather than twenty-year-old indexing engines. But their function remains the same. Call it whatever you want. It needs to be one system, not many and it doesn’t care what you call it.
The Shift Is Not Just Technical. It Is Organizational.
What is interesting to note about these new entrants in the SIEM or security analytics space is not just their security architecture. It is the company architecture. Modern security startups are being built on AI-native operating systems: Sales calls are captured and analyzed, not just by sales, but product teams mine them for competitive signals, marketing uses them to refine messaging, engineering uses them to prioritize roadmaps. This is not a tooling upgrade. It is a fundamentally different operating model.
Imagine a system where the vision, mission, strategy, and priorities are centrally maintained, updated and codified. Every function consumes that shared intelligence to drive decisions, messaging, and execution. This does not just improve alignment. It dramatically compresses learning cycles and execution speed. And that, more than any individual feature, may be the hardest thing for incumbents to replicate.
And why most of the arguments do not hold up under scrutiny
Over the past 18 to 24 months, venture capital has flowed into a fresh wave of SIEM challengers including Vega (which raised $65M in seed and Series A at a ~$400M valuation), Perpetual Systems, RunReveal, Iceguard, Sekoia, Cybersift, Ziggiz, and Abstract Security, all pitching themselves as the next generation of security analytics. What unites them is not just funding but a shared narrative that incumbent SIEMs are fundamentally broken: too costly, too siloed, too hard to scale, and too ineffective in the face of modern data volumes and AI-driven threats.
This post does not belabor each startup’s product. Instead it abstracts the shared assertions that justify recent funding and then stresses them to see which hold up under scrutiny. I am not defending incumbents. I am trying to separate real gaps from marketing (and funding) narratives.
The “SIEM is Broken” Narrative
A commonly cited industry report claimed that major SIEM tools cover only about 19% of MITRE ATT&CK techniques despite having access to data that could cover ~87%. That statistic is technically interesting but also deeply misleading: ATT&CK technique coverage is not an operational measure of detection quality or effectiveness, it primarily reflects rule inventory and tuning effort. Nevertheless, it has become a core justification for the “SIEM is obsolete” narrative. I wasn’t able to find the original report to validate what and how they tested, but I have seen SIEMs that cover much more and have big detection teams taking care of these issues.
The Five Core Claims Driving the Market Thesis
Across decks, interviews, and marketing copy, I picked five recurring themes that define what these companies think incumbents get wrong and what investors are underwriting as the path forward.
1. “Centralized SIEM architectures no longer scale”
The claim is that forcing security telemetry into a centralized repository is too expensive and too slow for modern enterprises generating terabytes of logs every day. The proposed fixes include federated queries, analyzing data where it lives, and decoupling detection from ingestion so you never have to move or duplicate all your data.
The challenge is that correlation, state, timelines, and real-time detection require locality. Distributed query engines excel at ad-hoc exploration but are not substitutes for continuous detection pipelines. Federated queries introduce latency, inconsistent performance, and complexity every time you write a detection. Normalization deferred to query time pushes complexity into every rule. You do not eliminate cost, you shift it to unpredictable query execution and compute costs that spike precisely when incidents occur. Centralizing data isn’t a flaw; it is a tradeoff that supports correlation engines, summary indexes, entity timelines, and stateful detections that distributed query models struggle to maintain in real time. In fact, if the SIEM was to store the data in the customer’s S3 bucket, you can keep cost somewhat under control.
2. “SIEM pricing is broken because it charges by data volume”
A frequent refrain is that incumbent SIEMs penalize good security hygiene by tying pricing to ingestion volume, which becomes untenable as data grows. The proposed response is pricing models untethered from volume, open storage, and customer-controlled compute.
The challenge is that cost doesn’t vanish because you hide volume. Compute, memory, enrichment, retention, and query costs all remain. If pricing is detached from ingestion, it typically reappears as unpredictable query charges, usage tiers, or gated features. Volume is not an arbitrary metric; it correlates with the cost a vendor (or customer) incurs. Treating cost as orthogonal to data volume does not make it disappear; it just blinds you to a key cost driver. I have dealt with all the pricing models: by user, by device, by volume, … in the end I needed to make my gross margins work, guess who pays for that?
3. “SIEM detections are weak because they rely on bad rules”
New entrants commonly assert that traditional SIEM rules are noisy, static, and unable to keep up with modern threat techniques. Solutions offered include natural-language detections, detections-as-code, continuous evaluation, and AI-generated rules.
The challenge is that many of these still sit atop the same primitives. For example, SIGMA is widely used as a community detection language, but it is fundamentally limited: it is mostly single-event, cannot express event ordering or causality, has no native temporal abstractions or entity-centric modeling, and cannot natively express thresholds, rates, cardinality, or statistical baselines. Wrapping these limitations in AI or “natural language” does not change the underlying detection physics. You can improve workflow and authoring experience, but you do not fundamentally invent a new class of detection with the same primitives. And guess what, large vendors have pretty significant content teams – I mean detection engineering teams – often tied into their threat research labs. Don’t tell me that a startup has found a more cost effective and higher efficacy way to release detection rules. If that were the case, all these large vendors would be dumb to operate such large teams.
4. “SIEMs lack context, causing false positives”
The argument here is that existing SIEMs flood analysts with alert noise because they lack deep asset context, threat intelligence, or behavioral understanding. New entrants promise tightly integrated TI feeds, cloud context, or built-in behavior analytics.
Context integration has been a focus of incumbent platforms for years. The real hard problem is not accessing context but operationalizing it without drowning analysts. More feeds often mean more noise unless you have mature enrichment pipelines, entity resolution, and risk scoring built into rules that understand multi-stage attack sequences. Adding more sources does not automatically improve signal quality. The noise problem is as much about rule quality and use-case focus as it is about context availability. Apply the same argument here with regards to the quality of threat feeds that I outlined in the last item.
5. “AI-native SIEMs will finally fix detection and response”
Perhaps the most seductive claim is that incumbent SIEMs were built for a pre-AI world and that new platforms built with agentic AI at every layer will finally crack automation, detection, and investigation.
The challenge is that AI does not eliminate the need for structured, high-quality, normalized data, or explainability, or deterministic behavior in high-risk contexts. AI can accelerate workflows, assist with investigation, and suggest hypotheses, but it does not replace the need for precise, reproducible, and auditable detection logic. Most AI-native claims today are improvements in UX and speed, not architectural breakthroughs in detection theory.
The Uncomfortable Conclusion
VC money is flowing because SIEM is operationally hard, expensive, and often unpopular with SOC teams. There is real pain and real gaps, especially around cost transparency, scaling, and usability. But declaring existing SIEMs obsolete because they are imperfect is not a thesis; it is a marketing slogan.
The core assumptions driving this funding wave deserve scrutiny: centralization is treated as a flaw rather than a tradeoff necessary for continuous detection, pricing complaints get conflated with architectural insights, detection quality is blamed on tooling rather than operational realities, and AI is overstated as a panacea.
On the flip side, here are a couple of directions that should be looked at:
Some of the new entrant SIEMs actually make a dent. They are rebuilding their entire pipelines and storage architecture with modern technologies, not old paradigms. They have a clear advantage and don’t have to deal with millions of lines of tech debt. Using an agentic AI architecture could be quite interesting here.
As the AI SOC emerges – and maybe become a reality – we will probably see more and more MCP servers exposing infrastructure information that can be leveraged, from alerts to context to response capabilities. But we’ll need to see how data schemas and all that will evolve.
The one innovation that has already generated some returns for investors is the entire data pipeline world. Companies like Observo (I had the privilege to be an advisor) have truly added something useful to the SIEMs and as I argue in one of my previous blogs, needs to really become a capability baked into each SIEM out there.
Every few years in security, a category shows up that makes you think: “This market should have never existed.”
The “security data pipeline / data fabric / routing” universe is exactly that. Impressive companies in the space, smart founders, great execution and (thank you Observo!) great exists already. But the fact that there is a market here is the real indictment. This category is nothing more than a gap SIEM vendors left wide open. And the pipelines walked right in.
A Market That Shouldn’t Exist
Let’s be honest: Splunk, Elastic, Sentinel, Exabeam… they all ignored the ingest problem for too long. Cost, routing, shaping, tiering — none of it was solved cleanly. So Cribl et al solved it for them. But here’s the twist. By solving it, they also became the neutral abstraction layer. The thing sitting between customers and their SIEM. That layer is now the switching fabric. It isn’t just “optimize your Splunk bill.” It’s:
Reduce SIEM ingestion.
Store everything in our “cheap” data lake.
Oh, and here’s some lightweight analytics while you’re here.
Or how about you go ahead and try out another SIEM? We can easily forward your data to multiple places while you evaluate moving away and then switching in a matter of hours.
That’s the Trojan Horse. You invite it in to help. And suddenly it controls the keys to the castle.
History Is Repeating Itself
We’ve seen this play before:
UEBA -> first standalone products slowly morphed into adding data stores, analytics, and then became full SIEMs
SOAR -> got absorbed into SIEM
Ingest pipelines -> now becoming lakes -> and eventually a SIEM
Cribl already has Cribl Lake. Give it time and it becomes a SIEM-lite. Then a SIEM.
This is the cycle: Start as an add-on -> become indispensable -> become the platform.
We keep acting surprised. But it’s the same movie every time. And again, keep thinking about the switching costs. This layer enables every customer to easily evaluate new solutions and switch over fairly easily.
If You’re Splunk… I mean Cisco…
You’re one of the few players that can still turn this around — if you execute sharply and fast.
Here’s what Splunk must own again:
Reclaim the ingest pipeline.
Make cost the advantage, not the penalty.
Federate search across data lakes natively. (I think you are almost there)
Make tiering and reduction a first-class feature.
Kill the routing layer through pure convenience.
Figure out your real-time story. Crowdstrike is going strong on messaging how fast attackers act these days and a batch approach won’t work anymore.
If Splunk doesn’t own the control plane, Cribl will. And once you lose the control plane, you lose the customer. No matter how good your detection content is. Cisco gives Splunk a rare opportunity: distribution, integration leverage, and a chance to fix what was ignored for too long. But they can’t let another category grow unchecked. Not again.
My Take
Data pipeline products aren’t the problem. They are the symptom.
The problem is the complacency that let the ingest layer drift outside the SIEM in the first place. Because once a neutral fabric handles all your data, the SIEM becomes swappable. The next SIEM won’t start as a SIEM. It will start exactly where Cribl started; as a pipeline (Abstract Security, anyone)? That’s the Trojan Horse.
Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
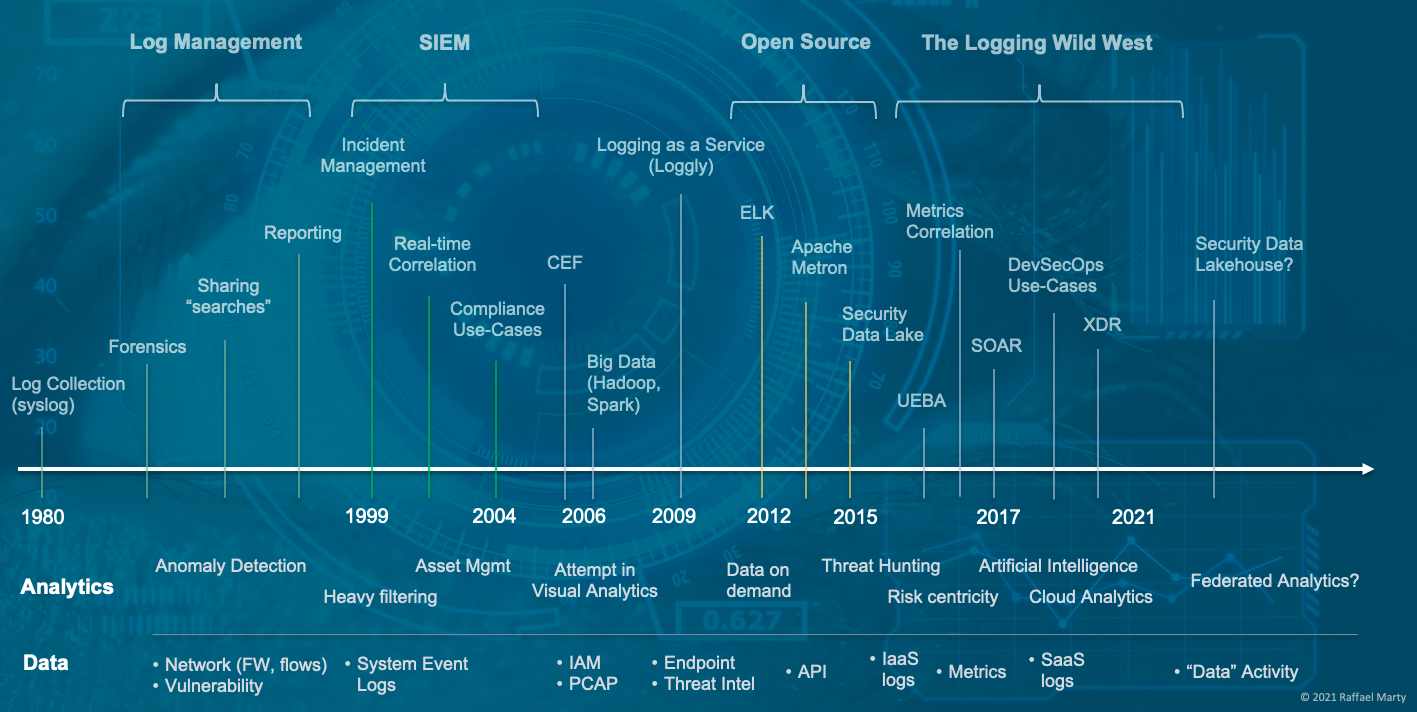
The log management and security information management (SIEM) space have gone through a number of stages to arrive where they are today. I started mapping the space in the 1980’s when syslog entered the world. To make sense of the really busy diagram, the top shows the chronological timeline (not in equidistant notation!), the second swim lane underneath calls out some milestone analytics components that were pivotal at the given times and the last row shows what data sources were added a the given times to the logging systems to gain deeper visibility and understanding. I’ll let you digest this for a minute.
What is interesting is that we started the journey with log management use-cases which morphed into an entire market, initially called the SIM market, but then officially being renamed to security information and event management (SIEM). After that we entered a phase where big data became a hot topic and customers started toying with the idea of building their own logging solutions. Generally not with the best results. But that didn’t prevent some open source movements from entering the map, most of which are ‘dead’ today. But what happened after that is even more interesting. The entire space started splintering into multiple new spaces. First it was products that called themselves user and entity behavior analytics (UEBA), then it was SOAR, and most recently it’s been XDR. All of which are really off-shoots of SIEMs. What is most interesting is that the stand-alone UEBA market is pretty much dead and so is the SOAR market. All the companies either got integrated (acquired) into existing SIEM platforms or added SIEM as an additional use-case to their own platform.
XDR has been the latest development and is probably the strangest of all. I call BS on the space. Some vendors are trying to market it as EDR++ by adding some network data. Others are basically taking SIEM, but are restricting it to less data sources and a more focused set of use-cases. While that is great for end-users looking to solve those use-cases by giving them a better experience, it’s really not much different from what the original SIEMs have been built to do.
If you have a minute and you want to dive into some more of the details of the history, following is a 10 minute video where I narrate the history and highlight some of the pivotal areas, as well as explain a bit more what you see in the timeline.
Thanks to some of my industry friends, Anton, Rui, and Lennart who provided some input on the timeline and helped me plug some of the gaps!
If you liked the short video on the logging history, make sure to check out the full video on the topic of “Driving Value From Security Data”
We have been collecting data to drive security insights for over two decades. We call these tools log management solutions, SIMs (security information management), and XDRs (extended detection and response) platforms. Some companies have also built their own solutions on top of big data technologies. It’s been quite the journey.
At the upcoming ThinkIn conference that LogPoint organized on June 8th, I had the honor of presenting the morning keynote. The topic was “How To Drive Value with Security Data“. I spent some time on reviewing the history of security data, log management, and SIEM. I then looked at where we face most challenges with today’s solutions and what the future holds in this space. Especially with the expansion of the space around UEBA, XDR, SOAR, and TIP, there is no such thing as a standardized platform that one would use to get ahead of security attacks. But what does that mean for you as a consumer or security practitioner, trying to protect your business?
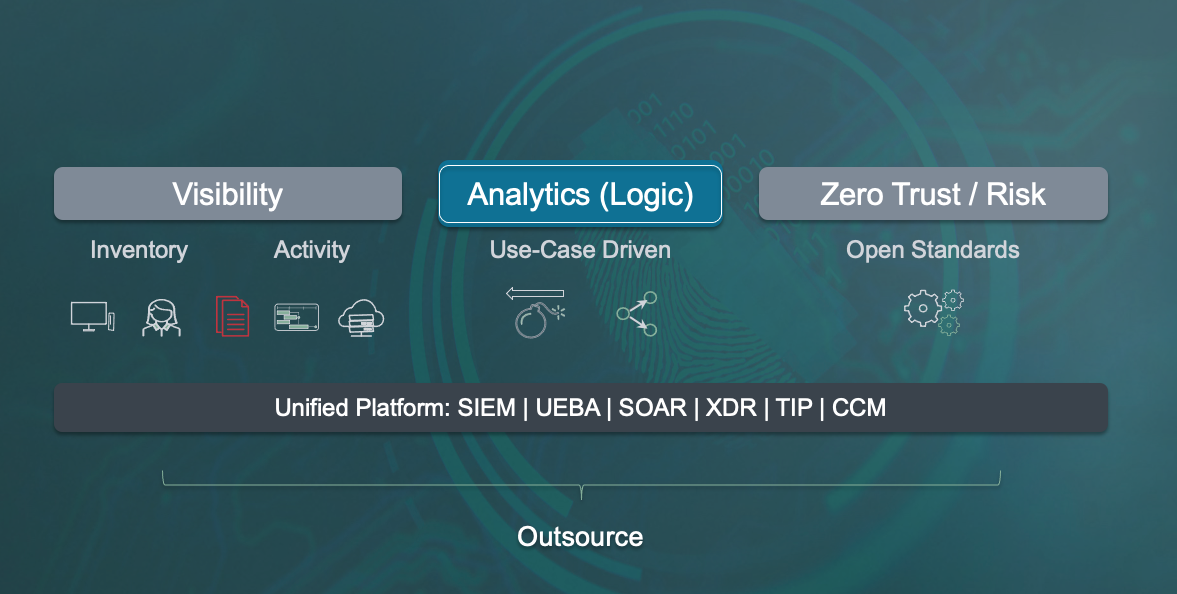
Following is the final slide of the presentation as a bit of a teaser. This is how I summarize the space and how it has to evolve. I won’t take away the thunder and explain the slide just yet. Did you tune into the keynote to get the description?