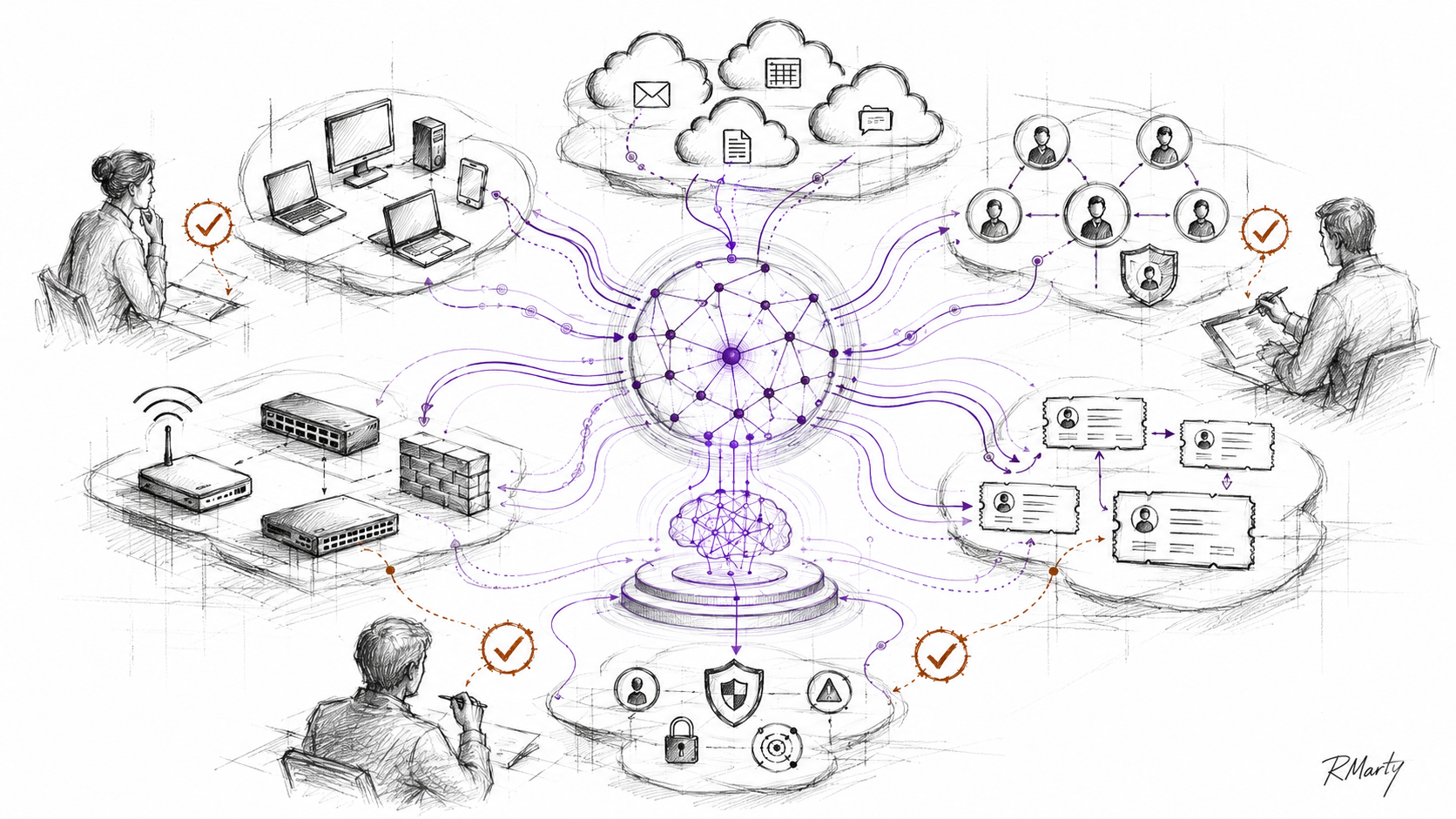
In the last two MDR posts, I looked at how MDR has to move beyond alert triage. First, the natural MDR extensions: asset and control coverage, exposure management, SIEM and data quality, cloud and identity posture, response orchestration, and proof that risk actually went down. Then, the deeper architecture: next-gen MDR as an AI-native SecOps control plane, where services become more productized, SIEM becomes symbiotic, and detection has to move into governed response.
This post is the next layer out.
Most conversations around AI in the MSP ecosystem still focus on copilots, workflow automation, and operational efficiency. Those are important, but they miss the larger transition underway. AI is forcing a redesign of the operational infrastructure underneath managed services itself, creating new platform dynamics and potentially large capital market opportunities across the SMB technology stack.
If MDR is becoming an AI-native SecOps control plane, what happens to the broader MSP market? My view is that the same operating shift is coming there too, but with a wider scope. The best MSPs will not just add AI to tickets, service desks, and support workflows. They may become the AI operations layer for SMB and mid-market infrastructure. That is a much bigger idea than “AI for MSPs.”
Services Are Becoming Software-Defined
Historically, software scaled and services did not. Services were people-heavy, exception-heavy, and hard to standardize. Good MSPs could improve process, stack discipline, and technician leverage, but the model still depended heavily on human execution.
AI changes part of that equation.
Support, remediation, governance, workflow routing, escalation, documentation, compliance evidence, and customer reporting can all become more software-defined. That does not eliminate the human operator. It changes the operator’s job from doing every step manually to designing, supervising, validating, and improving the operating loop.
This is why the boundaries between MSP, MDR, SaaS, outsourcing, and consulting start to blur. A managed service that is telemetry-driven, API-connected, AI-assisted, and outcome-accountable begins to look less like a traditional services business and more like an operating platform with humans in the loop.
MDR is one version of this. MSP is the broader version.
Copilot Is Not The End State
A lot of current AI messaging still sounds like copilot: summarize a ticket, draft a response, help an analyst investigate faster, recommend the next step, generate a report. That is useful, but it is not the final state. The customer is not really buying a better chat interface. They are trying to buy operational confidence.
For MSPs and MDR providers, the value stack is moving in this direction:
Old Value
Transitional Value
Future Value
Tools
Workflows
Outcomes
Tickets
Orchestration
Operational continuity
Alerts
Investigations
Risk reduction
Dashboards
Recommendations
Governed action
Labor
Automation
Confidence with accountability
This is where MSP and MDR converge. The customer does not want a PSA queue, RMM console, SIEM, EDR tool, dashboard, or pile of alerts. They want uptime, resilience, recoverability, compliance, secure productivity, fewer surprises, and someone accountable when the system does not behave the way it should. The product becomes operational confidence.
The Hard Part Is Operational State
This is also where a lot of “AI-first MSP” thinking is still too shallow. The hard part is not putting an LLM on top of a ticket queue. The hard part is knowing enough about the operating environment to take action safely. To automate IT and security operations, the system needs to know what exists, who owns it, what it connects to, what is business-critical, what policy applies, what telemetry is missing, what action is allowed, what could break, who can approve, how to roll back, and whether the action worked.
That requires an operational middleware layer:
Layer
Why It Matters
Asset and identity context
The system needs to know who, what, privilege, ownership, and business impact.
Telemetry quality
AI cannot reason well over missing, stale, or badly shaped data.
Workflow routing
The platform has to know when to automate, escalate, notify, or wait.
Policy and authority boundaries
Automation needs clear limits on what it is allowed to do.
Action and rollback controls
Remediation has to be safe enough for production environments.
Evidence and reporting
The provider must prove what changed, not just that work was performed.
This should sound familiar from the MDR discussion. The same architecture problems show up again: context, telemetry, workflow, policy, action, proof. The difference is that MSPs operate across a wider surface area. They touch endpoint management, identity, SaaS administration, backup, patching, compliance workflows, help desk, procurement, user onboarding, security tooling, and business continuity. That makes the AI opportunity larger, but it also makes the operating problem harder.
This is also why I am a proud advisor to FlowMind. They are tackling this problem from exactly the right angle: building a context graph across IT, network, cloud, and security knowledge, then using that context to automate ticket triage, investigation, and response. The important part is not just classifying the ticket faster. It is understanding the live customer environment well enough to recommend or execute the right fix.
AI-First MSP Is A Refounding, Not A Feature Upgrade
The phrase “AI-first MSP” can make the transition sound easier than it is. A true AI-native provider probably needs a different labor model, pricing model, knowledge system, telemetry stack, escalation chain, customer contract, operating metric set, and governance architecture. That is closer to a refounding than a modernization project.
The old MSP model optimized for human leverage: more endpoints per technician, better ticket workflows, tighter vendor standardization, and stronger recurring revenue. The next model has to optimize for governed automation: more safe actions per operator, better telemetry coverage, faster remediation loops, clearer authority boundaries, and stronger proof of outcome.
That also changes what investors and strategic acquirers should underwrite. Scale alone is not enough. Recurring revenue alone is not enough. A large MSP platform with fragmented tools, weak data architecture, inconsistent telemetry, and human-heavy workflows may not be an AI-native operating platform. It may just be a large labor organization with good retention.
The quality question becomes more operational: can this provider turn distribution, trust, and access into a compounding operating system?
The Practical Test
The test is not “does this MSP have AI?” That question is already too shallow. The better test is whether the provider can answer a few operating questions consistently:
Question
Why It Matters
What does the provider actually know about the customer environment?
AI leverage depends on accurate asset, identity, telemetry, and business context.
Which actions can be automated safely?
The value is not automation volume. It is governed action without breaking the customer.
Where does human approval still matter?
Autopilot still needs escalation, exception handling, and accountability.
Can the provider prove risk or operational burden went down?
Activity reporting is not enough if the outcome is confidence.
Does the operating model improve with scale?
The best platforms should compound knowledge and workflow quality across customers.
This is where diligence should move. Not just gross retention, endpoint count, technician utilization, or EBITDA margin, but whether the operating architecture is actually becoming more software-defined over time.
Distribution Is The Hidden Asset
The strongest strategic asset in the MSP market may not be the software stack. It may be the distribution layer.
MSPs already have something most AI vendors want and cannot easily build: trusted access into the SMB technology environment. They often have admin rights, endpoint access, SaaS integrations, procurement influence, business continuity responsibility, and a working relationship with the customer. That matters because SMBs generally do not have the internal capacity to manage AI transformation, AI governance, security operations, identity, SaaS posture, and workflow automation on their own. If AI agents become part of the workforce, somebody has to manage the operating environment around them. Identity, permissions, logging, workflow access, data boundaries, compliance, security, and incident response all have to extend from human employees to semi-autonomous systems.
That creates a larger role for the best MSPs and MDR providers. They can become SMB operational governance providers, not just outsourced IT or security teams.
The Market Will Not Reward Everyone
The dangerous assumption is that AI automatically increases the value of MSPs. It might. But it could also compress margins, reduce switching costs, commoditize service delivery, centralize operational intelligence in large platforms, and move value toward Microsoft, hyperscalers, or AI-native software vendors. The providers that benefit most will be the ones that turn service delivery into a software-defined operating model. The providers that only add AI features to the old model may see the opposite effect: more pricing pressure, less differentiation, and less tolerance for messy delivery. This is the broader implication of the AI-native MDR thesis. MDR may become the SecOps control plane. MSPs may become the operations and governance layer for the rest of the SMB technology stack.
The categories may keep their old names for a while: MSP, MDR, MSSP, SaaS, GSI, AI SOC. But the operating model underneath them is changing. The strategic question is no longer just who manages the tools. It is who becomes trusted to operate the customer environment as AI becomes part of the workforce.
MDR is not going away, but the old model is. The old model was service-first: collect alerts, have analysts investigate them, escalate what matters, and report what happened. That still solves a real problem, but it is not where the market is going.
The future MDR has to become product-first, AI-native, and action-oriented. It cannot just sit on top of EDR alerts and add analyst labor. It has to become the SecOps control plane that connects detection, investigation, response, exposure reduction, and proof of outcome.
This is not just an “AI layer” on top of alerts. It requires a different architecture, a different relationship with the SIEM, and a different operating model for response.
The Service Business Has To Become A Product Company
Traditional MDR was built as a service business. The product was often the people: analysts, playbooks, escalations, customer calls, and reporting. That model can scale to a point, but it starts to break when the market expects software-speed investigation and response.
Next-gen MDR has to invert the model. The platform becomes the core product, and services become the trust, expertise, and exception-handling layer around it. The test is margin and labor leverage. If more customers create more exceptions, more tuning, and more analyst burden, the company is still a service business. If more customers create more reusable detections, known-good patterns, automation recipes, and response policies, the service is becoming a product. Analysts still matter, but they should supervise, improve, validate, and handle edge cases. They should not be the primary execution engine for every repetitive investigation.
That is a hard transition because many MDR providers are not software companies. They can script, tune, and operationalize, but building a real SecOps platform is a different muscle.
The Moat Is Not AI. It Is Encoded Operational Judgment.
The defensible part of next-gen MDR is not that it uses AI. Everyone will use AI. The defensible part is whether the provider has converted years of SOC judgment into productized decision systems: known-good behavior, investigation procedures, response playbooks, customer-specific rules of engagement, approval policies, and feedback loops that improve the platform over time.
The best MDR providers will not simply have analysts assisted by AI. They will have a compounding operating system where every resolved case can improve future triage, investigation, automation, and response across customers. The weak version is service history trapped in analyst memory and exception lists. The strong version is structured, versioned, measurable operational knowledge embedded into the platform.
And let’s not forget the context graph. The data structure that learns the customer environments. The intelligence layer that fuses together individual data points to deliver a high signal, low friction security outcome.
MDR And SIEM Become Symbiotic
It’s a mistake think (or build a company around) next-gen MDR replaces the SIEM.
The SIEM is there for a reason. It stores logs, supports compliance retention, enables historical search, runs detections, and gives the customer a system of record for security data. Many customers already have years of detection logic, parsers, dashboards, and workflows inside it.
But the SIEM should not be the only operating layer for MDR. If MDR depends entirely on the (customer’s) SIEM, it inherits the SIEM’s latency, schema problems, data opacity, cost model, and workflow limitations.
The future relationship is symbiotic. MDR should use the SIEM’s detection layer where it works, but also audit it, monitor it, and improve it. Are the right logs arriving? Are detections still firing correctly? Are parsers broken? Are detections duplicated, stale, or missing context? Which investigation outcomes should feed back into detection logic?
In that model, the SIEM becomes less of the SOC’s user interface and more of a data and detection layer inside a broader SecOps operating system. It’s also feasible to have the SIEM be the data backend for the AI SOC, but only if it’s under the uninhibited control of the MDR.
AI Changes The Architecture, Not Just The Interface
The visible change in the near future is that analysts and customers will interact with the system(s) through AI. They will ask questions, start investigations, summarize cases, generate response plans, even design their own dashboards, and check what changed.
But the harder shift is underneath. The backend has to be built so AI can interact with it safely and efficiently. That means the platform needs clean APIs, stable entity models, permission-aware access, auditable actions, reusable investigation workflows, and compact context that does not require dumping endless raw logs into a model. And last but not least, the backend has to be designed for AI workloads and in turn, for token efficiency and for the types of (probably very suboptimal) queries that the AIs will send down.
This is why an AI-native SecOps platform is not the same as a chatbot on top of a SIEM. The architecture has to support the way AI investigates, acts, remembers, and learns.
Detection Has To Move Into Automated Response
The current MDR model still assumes a human-centered response loop: a detection fires, an analyst investigates, and someone decides whether to isolate, disable, block, remove, patch, ticket, or escalate. That loop is too slow for many modern attacks.
The future MDR platform has to move toward detection-to-response automation, but not reckless automation. Customers will push back, and rightly so. They do not want an opaque AI system taking production-impacting actions on its own. The answer is to be precise about what “AI” means.
Not every workflow needs an LLM. Much of response should become deterministic rules, policy engines, and pre-approved playbooks. GenAI should be reserved for the places where it helps: summarization, investigation planning, evidence interpretation, query generation, and edge-case reasoning. For most alerts, the system should be predictable, auditable, and constrained.
The second answer is supervision. Some actions can be fully automated. Some should require analyst approval. Some should require customer approval. The platform has to know the difference between removing a malicious email, disabling a privileged identity, isolating a production server, and changing access policy for a sensitive application.
The third answer is guardrails. We are entering the era of validation loops for AI: agents and control layers that check what the system proposes, understand disruption risk, enforce policy boundaries, and monitor whether the action worked. Formal guardrail frameworks, policy-as-code, approval gates, rollback paths, evals, and audit trails become part of the SecOps architecture.
This is where risk becomes the control signal. A suspicious event on a low-value test asset should not trigger the same response as the same event on a privileged identity accessing sensitive data. Risk should influence not only the analyst queue, but also resource access flows: step-up authentication, zero trust enforcement, restricted data access, endpoint isolation, email removal, identity reset, or escalation to a human.
That is the important shift. Detection should not only create an investigation. It should drive protection and exposure reduction.
The Market Implication
Next-gen MDR, AI SOC, and the MSP/MSSP security platform may look like separate markets today. Architecturally, they are converging. The packaging changes by segment, but the platform direction is increasingly the same.
Segment
What they have
What they actually need
Winning operating model
Failure mode
Enterprise
Internal SOC, SIEM, EDR/NDR, cloud, identity, often MDR already
Offload repetitive investigation, compress L1/L2 work, accelerate response, preserve control of L3 and security ownership
AI-native SecOps platform with optional managed expertise
Becomes another SOAR/chatbot layer that still requires too much engineering
Upper mid-market
Some SOC capacity, fragmented tools, inconsistent operations
Co-managed investigation and response, direct integrations, automation with customer control, risk/context model
Productized MDR / managed SecOps control plane
Gets squeezed by enterprise AI SOC platforms above and classic MDR below
Core mid-market
Limited security staff, enough maturity to respond, uneven tooling
Hybrid AI plus expert MDR, guided response, exposure visibility, outcome reporting
Next-gen MDR with embedded automation and human supervision
Stays stuck in analyst-assisted alert triage
SMB
Little or no security staff, MSP-led IT, low tolerance for complexity
MSP/MSSP-delivered security bundle with embedded MDR automation
Too many separate tools, too many escalations, no customer-side owner
Enterprise buyers will usually want to retain ownership of security operations. They may use managed expertise, but they are more likely to buy an AI-native SecOps platform that compresses L1/L2 investigation, improves consistency, and accelerates response while their internal team keeps control of higher-risk decisions. There is an opportunity for AI SOC players to provide the new sec ops platform for these enterprises as the central command – AI first, SIEM symbiotic.
Mid-market buyers are the most interesting and the most difficult. They often have enough security maturity to know they need help, but not enough staff or process maturity to run a pure platform themselves. This is where productized MDR can become the managed SecOps control plane: part platform, part expert service, part automation layer. The provider has to help operate the loop, not just forward alerts. The lesson is not to bolt on every adjacent service. Exposure management, asset visibility, identity posture, vulnerability prioritization, and response orchestration all matter, but they have to reinforce the MDR operating loop. If the provider adds too much service scope without product leverage, it becomes broad, expensive, and hard to deliver. This is also where we need the vendors to educate the market. Mid-market companies need these capabilities whether they ask for them or not. If they are buying separate tools for exposure management, asset inventory, vulnerability management, identity posture, and reporting, it is reasonable to ask why the MDR provider should not help operate those workflows. The customer can still supervise decisions, set policy, and approve sensitive actions. But the MDR should increasingly coordinate the operating loop. Ideally MDR players will open up their platforms for end customers to co-deliver security results.
SMB buyers may never experience this as an AI SOC platform. They may experience it through an MSP or MSSP security platform that bundles endpoint, email, identity, compliance, patching, response, and reporting all within one simple, per user license. But underneath, the same direction applies: more product, more automation, more risk context, more proof.
The future MDR is not an AI layer on top of alerts. It is not a cheaper SOC. It is not a duplicate SIEM. And it is not a service desk with better automation. The future MDR is a productized SecOps control plane: symbiotic with the SIEM, directly integrated with the customer’s enforcement tools, risk-aware in how it prioritizes and responds, deterministic where safety matters, AI-native where reasoning helps, and measured by proof of risk reduction. The companies that win will be the ones that turn service experience into compounding product advantage. The companies that lose will still have analysts, alerts, dashboards, and AI summaries, but no real moat.
In a previous post about the adjacencies to the MDR market, I laid out a framework for how MDR needs to evolve beyond alert triage. The basic idea was that future MDR should not just be “EDR alerts plus analysts.” It should become the control plane for cybersecurity operations and cyber risk reduction.
This post goes one level deeper. If MDR is going to become that control plane, what capabilities actually need to sit closest to the operating loop? The strongest extensions are the ones that help MDR understand what exists, what is exposed, what telemetry is missing, what response should happen, and whether risk actually went down.
Asset And Control Coverage
This is the starting point. MDR cannot protect an environment it does not understand, so the provider needs to know:
What exists?
What is unmanaged?
What lacks EDR coverage?
What lacks vulnerability scanning?
What logs are missing?
Which assets are business-critical?
Which controls are present, absent, or failing?
Asset context turns MDR from generic alert review into prioritized operations. An alert on a test machine is not the same as an alert on a domain controller, cloud control-plane asset, payment system, build server, or executive endpoint. An exposed vulnerability on an internet-facing revenue system is not the same as the same CVE on a low-value internal host.
The future MDR has to understand this context automatically in a dynamic envirionment.
Exposure And CTEM
This is probably the most important adjacency. Classic MDR waits for something to fire. Exposure management asks what can be attacked before the alert exists.
The future MDR should know:
What is exploitable?
What is internet-facing?
What is business-critical?
What is currently being targeted?
What attack paths exist?
What should be fixed first?
Which exposures actually got closed?
This is what moves MDR from reactive monitoring to proactive risk reduction. The important distinction is that this cannot just be scanner reporting. Vulnerability management becomes an MDR extension only when it is tied to exploitability, asset criticality, identity paths, observed threat activity, and actual remediation workflow.
SIEM And Data Quality
MDR is only as good as the data it can use. That makes SIEM operations and data quality core to the future model, even if the MDR provider does not own the SIEM product.
The provider should know:
Are the right logs ingested?
Are important sources missing?
Are fields normalized?
Are detections using the right data?
Is retention sufficient?
Is query performance good enough for investigation?
Is SIEM cost being optimized?
This becomes more important as AI changes the interface to the SOC. If AI becomes the primary user of security data, the SIEM UI may matter less, but the quality, structure, accessibility, and completeness of the data matter more.
Cloud And Identity Posture
Modern attack paths increasingly run through identity, SaaS, cloud entitlements, workload permissions, and configuration mistakes. That means cloud and identity posture are not optional context for serious MDR.
The future MDR should understand:
Who can access what?
Which identities are overprivileged?
Which accounts are risky or stale?
Which cloud paths create attack chains?
Which workloads are exposed?
Which posture issues make detection or containment harder?
Without this context, MDR sees too little. It may detect a suspicious event, but miss the path that made the event possible.
Response Orchestration
The MDR has to respond faster than human-speed response, but safely. The system should be able to:
Isolate an endpoint
Disable or step-up an identity
Block an indicator
Remove malicious artifacts
Open and route tickets
Trigger patching or remediation workflows
Escalate to IR
Prove that the action happened
The word “safely” matters. MDR automation cannot become a blind SOAR playbook that breaks production. The provider needs policy, approvals, rollback paths, asset criticality, business context, and evidence that the response improved the situation.
What The Future MDR Should Prove
The old MDR output was an investigated alert. The future MDR output should be a safer environment. That changes the questions the service should answer:
What percentage of critical assets are covered by EDR, vulnerability scanning, identity telemetry, cloud telemetry, and relevant logs?
Which high-risk exposures were removed this month?
Which attack paths were closed?
Which detections improved because missing telemetry was fixed?
Which response actions were automated safely?
Which risks were accepted by the business?
Which risks were remediated?
Did measurable exposure go down?
This is the reporting layer that matters. Not activity reporting. Not “we reviewed this many alerts.” Not a dashboard that proves the provider was busy.
The stronger MDR report says: here is what exists, here is what is exposed, here is what we saw, here is what we did, here is what changed, and here is the risk that remains.
The Market Implication
The MDR market will split between alert-centric providers and control-plane providers. Alert-centric MDR can still be useful. Many buyers still need 24/7 investigation, escalation, and containment. But that model will be pressured by platform vendors, automation, and buyer expectations for more context.
The more defensible MDR provider will move upstream and downstream at the same time. Upstream, it owns asset context, control coverage, telemetry quality, exposure prioritization, cloud posture, and identity posture. Downstream, it owns containment, remediation orchestration, incident response, validation, and outcome reporting.
That is the future MDR control plane. The category may keep the same name, but the job changes from outsourced alert handling to command central for cyber risk reduction.
I will follow up on this with another MDR post to explore some topics a bit more, such as:
MDR started as a practical answer to a very real problem: customers had too many security alerts, too few security operators, and no realistic way to staff a strong 24/7 security operations center (SOC). That problem still exists. Fast investigation and response are still table stakes. But the category has to move beyond “EDR alerts plus analysts.” The MDR of the future is not just a better alert triage desk. It is the control plane for cybersecurity operations and cyber risk reduction. The winning MDR will own the loop from what assets exist, to what is exposed, to what telemetry is missing, to what detection fired, to what response should happen, to whether risk actually went down.
The Adjacency Test
In the following post I am exploring how MDR will need to evolve into the future. What adjacent markets are of importance and how can MDR solutions expand their services to help secure organizations?
The adjacency test to understand whether a use-case or product or service should be added to the original MDR service is simple: Does this capability make MDR better at preventing, detecting, prioritizing, responding, or proving risk reduction? If yes, it is a natural MDR extension. If not, it may still be a good product, but it is probably not core MDR.
With that, I’ll be using the following scale to rate various adjacent capabilities:
Score
Meaning
5
Essential to future MDR
4
Very strong natural extension
3
Useful adjacency / segment-specific
2
Nice portfolio extension, not core MDR
1
Mostly unrelated / likely distraction
The Five Buckets
The future MDR stack can be organized into roughly seven buckets of use-cases that each contain multiple products or services themselves as I will outline below.
This is the shape of the future MDR control plane. The center of gravity is not just alert handling. The center is the operating loop that connects visibility, exposure, detection, response, and proof of improvement.
The Capability Map
Here is how I would expand the capabilities within each of the buckets and score them for MDR importance.
Detection & Response Core
Area / Capability
Importance
Why It Matters For MDR
MDR / alert triage
5
Table stakes. MDR must investigate, validate, prioritize, and respond to alerts.
XDR operations
5
Correlates endpoint, identity, cloud, email, and network signals into investigations.
Enables removal of malicious emails and containment of active phishing campaigns.
Human / user risk scoring
3.5
User risk should influence prioritization, investigation depth, and response decisions.
Security awareness signals
2.5
Useful if tied to risk scoring and phishing outcomes; weak if only training content.
Collaboration security signals
3
Teams, Slack, Google Workspace, and M365 activity increasingly matter for identity and phishing investigations.
Recovery & Resilience
Incident response / DFIR
4
MDR often becomes first responder; IR capability improves containment, investigation, and recovery.
Malware analysis
3.5
Helps with advanced investigations, detection improvement, threat hunting, and IR.
Ransomware readiness
3.5
MDR value is higher when it can assess containment, recovery paths, and blast radius.
Backup posture visibility
2.5
Important for ransomware outcomes, but MDR usually needs visibility rather than owning backup.
Recovery coordination
3
Helps translate detection and containment into business restoration during major incidents.
Enforcement Surfaces
Endpoint isolation
4.5
One of the most important response actions in MDR.
Identity disablement / reset
4.5
Critical for account compromise, lateral movement, and cloud incidents. Ideally enabled as a dynamic, continuous, risk-based action.
Email removal / quarantine
4
Necessary for phishing and business email compromise response.
Firewall rule changes / blocking
3.5
Useful for containment and network-level response, especially in traditional environments.
SASE / ZTNA enforcement
3
Relevant for modern access control, but usually an enforcement integration rather than core MDR product.
SOAR / ticketing orchestration
4
Operationalizes response through customer workflows and approval gates.
NAC / network access control
2.5
Useful for unmanaged devices and segmentation, but segment-specific.
Broader Portfolio
Third-party risk management
2.5
Relevant to enterprise cyber risk, but only loosely tied to MDR unless connected to active threats/exposure.
Digital risk protection / dark web monitoring
3
Useful external context for credential leaks, brand risk, and executive threats.
Native endpoint protection
3
Powerful if vendor owns the stack, but independent MDR can remain tool-agnostic.
Native email security
2.5
Useful portfolio extension, but MDR mainly needs email visibility and response control.
Native firewall / network security
2.5
Helpful for suite vendors, but not required for MDR differentiation.
Unified endpoint management
2.5
Full UEM is IT operations; MDR mainly needs endpoint context and remediation hooks.
WiFi management
1.5
Too far from MDR except in branch, retail, campus, or healthcare-heavy environments.
WiFi security
2.5
More relevant than WiFi management because rogue devices and network access affect exposure.
Security awareness training
2
Helpful risk-reduction add-on, but weak MDR moat unless connected to user risk and phishing outcomes.
GRC / compliance reporting
2
Useful for board and audit reporting, but not central to detection and response quality.
I will let this sit here as just categories for now and will outline in a future post what questions are underlying these categories to make the MDR service more effective and what this all means for the MDR market at large.
One of the more interesting messages going into RSA was not just that AI is reshaping security. It was that the market is changing what it rewards. I had the pleasure of attending the Piper Sandler investment day on Monday at RSA, one of my favorite events where I get to catch up with many friends, meet new security leaders and get an update on the security market conditions.
The market for cyber security companies last year was easier: grow fast, expand inside the account, add modules, and let NRR do the talking. The new story looks different:
ARR growth expectations have come down from 50% to 30%
Gross margin expectations have moved up from 75% to 80%
NRR expectations have come down from 120% to 115%
GRR expectations have moved up from 88% to 92%
Burn multiple expectations have tightened from 1.5x to <1.0x
That may sound like a generic software market shift. I do not think it is. I think it has very specific implications for AI SOC and SIEM. More about that later.
Capital markets changed first
The broader market backdrop matters. Security is still one of the more attractive areas in software, but it is being valued inside a much harder capital markets environment. The IPO window remains narrow. Liquidity for scaled assets is limited. Growth is decelerating across software. And AI is compressing valuations by making forward revenue less credible and product durability more important. That combination changes the conversation from upside to survivability.
Security is still attractive, but the bar is higher
That is why the security market now feels bifurcated. On one side, it still benefits from strong structural demand: geopolitical uncertainty, expanding attack surfaces, and AI itself creating new categories of spend. On the other side, investors are becoming much less willing to underwrite broad TAM stories, multi-year expansion narratives, or “we will grow into the model” margin profiles. Security remains attractive, but the bar is higher.
Private equity has a liquidity problem
Private equity is caught in that tension as well. Large assets are staying private longer because the public market is not offering a clean exit path. That creates pressure on hold periods, return profiles, and liquidity planning. More firms will need to create liquidity through secondaries, continuation vehicles, and other forms of fund-to-fund reshuffling rather than relying on traditional exits. That is not a theoretical issue. It shapes what kinds of assets still look financeable, what kinds of stories buyers will believe, and how aggressively firms can keep marking winners.
M&A gets more strategic from here
At the same time, strategic logic is getting stronger. Large-scale M&A should remain active because buyers still want growth, but they increasingly want growth that is accretive, platform-relevant, and commercially durable. The market is likely to reward scaled platforms, integrated environments, and assets that can either deepen data advantages or simplify the stack. It is likely to punish products that still depend on expensive customer education, loose positioning, or heroic expansion assumptions.
AI increases both risk and defensibility
AI only sharpens that divide. In security, AI is both a disruption risk and a source of defensibility. It creates fear around older architectures and weaker product moats, but it also increases the value of proprietary telemetry, embedded distribution, and control points across the enterprise. The winners are less likely to be those with the loudest AI messaging and more likely to be those with the strongest combination of data, workflow ownership, and commercial leverage.
Platformization is really about data gravity
That is also why platformization matters so much right now. This is not just a consolidation story. It is a data gravity story. The vendor that sees more telemetry, sits in more workflows, and becomes harder to dislodge can improve models faster, distribute new capabilities faster, and defend retention more effectively. In a market that now cares more about GRR, margins, and burn discipline, that matters a lot.
What this means for AI SOC and SIEM
This is where the implications for SIEM and AI SOC come into focus. The category is seeing real pressure from both sides: incumbent platforms facing pricing and architectural questions, and newer entrants offering better workflows, AI-native interfaces, and more agentic operating models. But the long-term winners may not be the vendors with the sharpest demo. They may be the ones that combine durable retention, meaningful use-cases, security outcomes, and enough platform surface area to remain central as the security stack becomes more automated and more agent-driven.
RSAC 2026 made one thing very clear to me: the market is moving fast, but it is still deeply confused. The big announcements from Google, Splunk, and Databricks all point in the same direction. Security operations are becoming more agentic, more API-driven, and more automated. But most of the category still looks crowded, early, and only lightly differentiated.
The interesting part is not that everybody now has an AI story. It is where the pressure is landing: attack speed, active response, and the possibility that AI itself becomes the primary user of the security stack.
TL;DR
Attacks are now fast enough that human-speed response is no longer a sufficient default.
That will push the market toward active response, which is useful but also dangerous if the control logic is not deterministic enough.
Most AI SOC vendors still sound similar because many of them sit on top of existing SIEMs and alert streams rather than changing the underlying detection or data architecture.
The big SIEM vendors are moving, and one major EDR/SIEM vendor is expanding AI security into on-prem and sovereign environments.
If AI becomes the user of security products, the UI matters less, the API matters more, and the economics of expensive SIEM platforms get harder to defend.
Attacks are getting faster
This is the part of the market I think people are still underestimating. CrowdStrike’s 2026 threat report says the average eCrime breakout time dropped to 29 minutes in 2025, and the fastest case it observed was 27 seconds. Databricks used its Lakewatch announcement to make a related point from the vulnerability side, citing research that mean time to exploit has fallen from 23.2 days in 2025 to 1.6 days in 2026.
That changes what matters in the SOC. A lot of SIEM workflows still assume there is time to search, enrich, discuss, and decide. That model was already strained. It gets worse when attacks speed up and when the adversary is using AI to compress its own loop. Search still matters, but a search-centric operating model is not enough if the environment can be compromised end to end in under an hour.
The obvious answer is more active response. The problem is that this is where things get dangerous. If teams start handing more containment and remediation decisions to AI before the systems are ready, we are going to see more self-inflicted outages. The market is moving there anyway, because the alternative is to keep defending at human speed against machine-speed attacks. SOAR was supposed to close part of that gap and clearly did not.
AI SOC is still confusing and mostly sounds the same
That was probably my main emotional reaction leaving RSAC: confusion. There were simply too many vendors with very similar messaging. RSAC says the conference had more than 600 exhibitors this year. I could not independently validate an exact count of 36 AI SOC vendors from public RSAC data, but “roughly three dozen” felt directionally right from the floor, and many of them sounded remarkably similar.
The common pitch was familiar: reduce alerts, triage faster, investigate faster, give the analyst a copilot, automate parts of response. Some of that is clearly useful. But a lot of it still feels like a layer on top of the existing SIEM rather than a rethink of the detection stack itself. If the AI mostly sits on top of alert streams coming out of a legacy backend, then it may improve analyst productivity without materially fixing false negatives, brittle detections, or poor data design upstream.
That is also why I do not think most of this market is really using LLMs in a deep way yet. In most cases, the models are being used for triage, recommendations, summarization, and analyst assistance. That is very different from using LLMs for real detection, broader SOC operations, or meaningful changes to the underlying architecture.
That is why so much of the category feels undifferentiated. The interfaces are different, the branding is different, and the demo flows are different, but the center of gravity often looks the same. The latest platform announcements only reinforce that point. If the platform owner adds the agentic layer too, the vendors sitting on top of Chronicle, Splunk, or similar platforms have a much harder moat to defend.
The architecture is shifting
By this point, the vendor movement is established. The more interesting question now is what it does to architecture. SentinelOne adds another signal here by pushing more AI security capability into on-prem, sovereign, and air-gapped environments.
Put together, that points to a broader market shift. Storage matters more. Data routing matters more. Sovereignty and local control matter more. Cheap data lakes, strong analytics layers, and flexible orchestration matter more. Traditional SIEM UI matters less than it used to, and that matters not just for SIEM vendors but also for MDRs that differentiated by putting an AI layer on top of someone else’s backend.
That is also why Splunk’s cost model keeps coming back into the conversation. Splunk is powerful and mature, but if the agent becomes the main consumer of the system, customers start asking a different question: am I paying for the analytics engine, or am I paying for UI, workflow, and operating complexity that an agent increasingly does not care about?
If AI becomes the user, the stack changes
The most important implication may be economic, not just operational. Security products were built for human analysts. The value lived in the UI, the workflow, the search language, the dashboard, and the services needed to make all of that usable. But what happens if the real user becomes Claude Code, Codex, Gemini, or some internal agent instrumented across the entire security stack? Daniel Miessler has been arguing that companies and products increasingly become APIs. Security looks like one of the clearest versions of that shift.
In that world, every product starts to look more like an API than an application. That is exactly where the recent announcements are heading. LimaCharlie’s new lc-soc release is a concrete implementation of the same idea: an open-source “agentic SOC as code” where AI agents are coordinated through the cases system and D&R rules, then deployed and versioned like infrastructure.
If AI becomes the primary user, the UI does not disappear, but it stops being the center of gravity. The agent does not care about your console. It cares about whether the data is accessible, whether the schema is consistent, whether the analytics layer is fast, whether the permissions model is clean, and whether the actions are safe to orchestrate.
That creates real pressure on expensive SIEM economics. If the agent can query multiple tools directly, the premium attached to a deeply monetized UI gets harder to justify. The market may move toward something simpler: cheap storage, a strong analytics layer, and an orchestration layer on top. That does not mean incumbents disappear. It means their value proposition changes. If AI becomes the user, the winners may be the vendors with the best APIs, control points, and data access model.
Evals become part of the control layer
The next problem is trust and determinism. Once you push AI beyond triage and recommendations and let it make or recommend more consequential changes, you need a way to keep the system reliable. That is where eval loops come in.
I heard Josh Saxe make this point at RSAC in the context of AI-first infrastructure management: if agents are going to make changes in live systems, you need strong evaluation around them to keep behavior bounded and repeatable enough to trust. I think the same logic applies directly to security operations. The market is moving toward active response, but the models themselves were not built around strict determinism.
That means the answer is not blind autonomy. It is more likely a layered system where adaptive AI sits inside clearer control boundaries, with evals, policy, and deterministic automation around it. Evals stop being an AI engineering detail and become part of the security control layer itself.
“AI lowers execution cost, not accountability. SMBs outsource accountability.”
It will affect SMB customers, the MSPs serving them, and the software vendors selling into the channel. Those are three different layers, and the impact on each one is different.
SMBs Still Do Not Want To Own the Problem
One concern is that AI makes knowledge cheaper and tooling easier, so SMBs may decide to manage more of their own IT.
I do not think that is the main outcome.
Most SMBs do not hire an MSP because they cannot access software or information. They hire an MSP because they do not want to own the problem. They want someone else to choose the tools, deploy them, keep them running, support users, stay current, and deal with issues when something breaks.
AI may make parts of IT easier. It does not remove the need for responsibility. That is why I think AI is unlikely to reduce the need for MSPs in any dramatic way.
MSPs Get More Leverage
Inside the MSP, the impact is more direct.
A lot of the work is repetitive: triage, ticket handling, investigation, internal knowledge lookup, and workflow coordination across too many systems. AI can improve all of that.
That does not mean the MSP becomes irrelevant. It means the MSP becomes more efficient.
A smaller team may be able to support more customers, resolve more issues, and operate with fewer manual steps. In security especially, where talent is scarce, that matters a lot. The near-term effect of AI on MSPs is not disintermediation. It is better leverage, better scale, and a different labor model.
MSP Software Vendors Face the Real Reset
The most interesting pressure may land on the MSP software vendors.
The issue is not whether they can add AI features. They all will. The real issue is whether they can get on the AI coding wagon fast enough and turn that into much faster product development.
AI-native development practices will increase the amount of software the market can produce. More gets built. Iteration cycles get shorter. Focused startups can come in faster. And incumbents lose some of the advantage that came from simply being large, embedded platforms.
That is where the moving-fast disadvantage shows up.
Big vendors carry legacy code, older architectures, complex customer requirements, and years of accumulated product sprawl. It is much harder for them to become truly AI-first development organizations than it is for a newer company starting fresh. There is a big difference between developers occasionally using AI and a company rebuilding product, engineering, testing, and delivery around AI-assisted speed.
If incumbents make that shift well, they will benefit enormously. If they do not, AI will not just improve their products. It will make newer competitors much more dangerous.
What Changes From Here
My current view is simple.
AI is probably a tailwind for MSP demand. It is clearly a lever for MSP efficiency. But it may be most disruptive to the software vendors serving the market, because it changes the speed of product development and lowers the barrier for new entrants.
MSPs are not going away. But the basis of competition is changing.
I recently joined Tim Peacock and Anton Chuvakin on the Google Cloud Security Podcast to talk about SIEM, AI SOC, pricing, federated architecture, detection engineering, and why network telemetry is quietly becoming important again.
The short version is simple: SIEM is not dead. Calling it obsolete makes for good marketing, but it is not a serious thesis.
The new wave of AI SOC, SIEM, and pipeline vendors is not proving SIEM is dead. It is proving SIEM vendors left too many gaps open for too long.
The recent wave of AI SOC startups, pipeline vendors, and new SIEM entrants is a response to real pain in the market. They are not replacing SIEM. They are capitalizing on the gaps incumbent vendors left open.
TL;DR
SIEM is not dead. Vendors just left too many gaps open.
AI SOC often exposes those gaps more than it replaces SIEM.
Alert reduction alone will hide false negatives.
The real fixes are better routing, detection, context, and workflows.
Network telemetry still matters more than the market narrative suggests.
The market is not replacing SIEM. It is rebuilding missing pieces.
They say they will reduce alert volume, improve detections, make investigations faster, lower storage costs, and simplify operations. None of that is new. Those were always core parts of the SIEM vision.
That is why so many of these new entrants exist. They found real gaps:
Pricing that became too hard to justify
Architectures that did not scale as well as they should
Detection stacks that still require too much manual work
Default content that creates too much noise
Workflows that remain painful for analysts and service providers
This is why I do not buy the “SIEM is over” narrative. If incumbents fix these gaps, many point solutions lose their edge quickly.
AI SOC is mostly a patch on downstream pain
The strongest short-term value in the AI SOC market is obvious: too many teams, especially MSSPs and down-market security providers, are drowning in alerts. A lot of environments are running with default content, light tuning, and limited budget for customization. Large enterprises can afford deep implementation and constant refinement. Many managed providers cannot.
If a product makes the SOC quieter without improving coverage, you may not have solved the problem. You may have just converted visible false positives into invisible false negatives.
If a startup is solving alert overload by learning that the same service-account misconfiguration fires every morning at 8am and can safely be deprioritized, that is useful. But it is still a patch on bad upstream logic, and it often hides a second problem: false negatives. Once teams see fewer alerts, they assume the system got smarter. Sometimes it did. Sometimes it just got quieter. The real fix belongs closer to the detection layer, the correlation logic, the content, and the configuration model.
That is why I think a lot of the current AI SOC wave is temporary in its present form. Not temporary because the need goes away, but temporary because the best parts of that value will be absorbed elsewhere. Some of it should move back into the SIEM. Some of it should live in the detection engine. Some of it belongs in better onboarding, better rule tuning, better data handling, and better defaults.
There is still room for new winners here. But “we reduce alerts by 80%” is not a durable thesis by itself.
The architecture debate is not centralized versus federated. It is about access patterns.
In theory, pushing compute to where the data sits is attractive. In practice, the answer depends on access patterns.
Some data absolutely does not need to be centralized all the time. Endpoint system calls are a good example. You do not want to shovel every low-level signal into a central platform by default if you can process, summarize, or prioritize it earlier.
But the moment an analyst, agent, or investigation workflow needs context, enrichment, and cross-correlation, some centralization comes back. You need to connect what happened on the endpoint with what happened on the firewall, identity plane, SaaS layer, email stack, and elsewhere.
So the future is probably not pure centralized or pure federated. It is hybrid:
Keep some data local or near-source
Route and centralize the parts that matter
Pull deeper context only when needed
Optimize around how investigations actually happen
This is why I keep coming back to smart data routing. Most organizations do not need to send every piece of data to the same place forever. But they do need an architecture that knows when to summarize, when to correlate, and when to pull more detail back in.
Data pipelines became the Trojan horse
Vendors in this space positioned themselves as optimization and routing tools. Send your data here, normalize it, trim low-value volume, route it to the right storage tier, keep costs down, and retain optionality. In many environments, that solved a real problem.
Once a pipeline vendor owns your ingestion layer and your integrations, it becomes an abstraction layer between you and the SIEM. That makes the SIEM less sticky. At first the pipeline vendor only routes data. Then it adds search. Then it runs lightweight detections. Then it supports simple rules. At some point it starts to look suspiciously like a simple SIEM.
If someone else owns the data path, they eventually get a shot at owning more of the security brain.
Pricing remains one of the category’s hardest unsolved problems
Almost everyone agrees that SIEM pricing has been a problem. Much fewer people agree on what the right answer is.
The vendor reality is straightforward: data volume drives cost. The customer reality is equally straightforward: they hate unpredictability.
That tension gets even worse in the service-provider world. MSSPs and MSPs often sell packaged services, per-user offerings, or per-device contracts. Their customers do not want a fluctuating bill because log volume spiked this month. So the thing that is economically clean for the vendor can be operationally ugly for the buyer.
There is no perfect answer here. But the next generation of pricing models will need to do a better job of separating:
Predictable commercial packaging
Actual backend resource consumption
Incentives for better data quality rather than more raw ingestion
The market has already started experimenting. Bring-your-own-storage, bring-your-own-compute, lower-cost data lakes, and more selective routing are all responses to the same pressure. Pricing is one of the core forces reshaping the market.
Detection engineering still needs much more help from the platform
Rules still need adaptation by environment. Thresholds differ. Data quality differs. Sources differ. Customer expectations differ. Generic content does not simply drop in and work.
What is surprising is how much low-hanging product work still remains. A modern platform should do far more to help users answer basic but critical questions:
Is the data required for this detection even present?
Is it configured in a way that can ever make this rule fire?
Are there obvious gaps or mistakes in the source configuration?
Which detections are silent because they are poorly mapped to the environment?
The more interesting direction, in my view, is not just better standalone rules. It is better context. Call it a context graph, an entity graph, a risk graph, or something else. The naming matters less than the function.
You want a living model of users, devices, applications, identities, behaviors, and risk signals. If the system knows that a user is coming from their normal IP, on a familiar device, through a known browser pattern, after strong authentication, that should shape how other events are interpreted. If all of those signals change at once, that should shape the response differently.
That kind of context is where detection quality meaningfully improves.
Network telemetry is not “back,” but it is still critical
I do not think this automatically means a major standalone NDR renaissance. But I do think many teams went too far in treating network telemetry as secondary once endpoint and application visibility improved.
An endpoint is still a single point of failure. If you lose visibility there, the network can still tell you a lot. It can help validate what else is happening. It can show you unmanaged systems, OT environments, choke points, and traffic patterns you will not otherwise see clearly.
This matters even more now because some organizations are reassessing where systems and data live. In parts of Europe, I am seeing more discussion around data sovereignty, political trust, private clouds, and selective moves back toward local or regional infrastructure. As architectures spread and governance constraints tighten, network visibility becomes more important again.
So no, I would not frame this as “throw away EDR and buy NDR.” That is the wrong lesson.
What happens next
The real question is not whether SIEM survives. It is which vendors understand they are now selling data architecture, detection quality, analyst workflow, and decision support.
The SIEM market is heading into another rebuild cycle. Some AI SOC and pipeline startups will disappear, some will be absorbed, and some incumbents will finally fix what they should have fixed years ago. But the core need is not going away: security teams still need a place where signals come together, context gets built, detections improve, and response decisions get made.
That is still SIEM territory, even if the implementation looks very different from what we used to buy.
? If you are building, buying, operating, or replacing SIEM, I’d love your input. I’m collecting market data at raffy.ch/SIEM. Anyone can contribute, and everyone is welcome.
Update: Instead of an Excel spreadsheet, here is an online app that you can use. I’d love for you to submit your own ratings so we can crowd-source some of these answers!
“Ok, but how do I evaluate vendors consistently without falling back into feature checklists and marketing claims?”
So I turned the framework into a practical scoring workbook (and now a small Web application) you can use to rate a platform across the dimensions I described in the post. The workbook allows you to rate each category from 1 to 5 and I spent some time defining what a 1 versus a 5 means in each of the categories. I give you an example for the “Data Pipeline Optimization” category. Here are the 5 maturity steps:
1 | Static ingestion pipelines that forward all data to a central store.
2 | Basic filtering or routing based on source or log type.
3 | Conditional enrichment and routing based on use case or predefined alerts/rules.
4 | Dynamic pipelines that adapt sampling, enrichment, and routing based on downstream value.
5 | Continuously optimized pipelines driven by feedback loops from detections, cost, and analyst outcomes.
I hope the breakdown into these 5 values helps going through a more ‘objective’ assessment of these platforms and also shows what excellent looks like in each of these categories.
What this is
The Security Analytics Platforms – Maturity Framework is an architecture-first tool to evaluate security platforms across architectural, detection, and operational dimensions. It is designed to help you compare systems based on their advanced capabilities that are desperately needed to deliver a SIEM experience that is adequate for 2026..
What this is not
This is not a vendor ranking, a feature checklist, or a replacement for hands-on testing. It’s also NOT an RFP template. As I indicated in my previous blog where I outlined all the different categories, the table stakes are not mentioned or evaluated.
How to use it in 10 minutes
Add one vendor per row in the rating sheet.
Score each topic based on current behavior, not roadmap promises.
Review category roll-ups and the heatmap to spot structural gaps.
A key insight: large gaps between category scores often matter more than the overall score.
Security analytics is in the middle of a reset. Incumbent SIEMs are being re-architected, new SIEM startups are emerging, and AI SOC vendors are rewriting parts of the operating model. End users and investors need a way to evaluate these platforms objectively, beyond feature checklists and marketing claims. This workbook is my attempt to make that evaluation repeatable, comparable, and anchored in the areas that I see missing or deficient in the incumbent SIEM space.
If you use it, I’d love your feedback
If you score a platform with it, use the Web app and submit your rating. You need to log in via Github or Google so I don’t get flooded with fake entries. I’d love to crowdsource an assessment of all the SIEM and AI SOC vendors out there. Can we do it?
I have been talking to a few AI SOC and new SIEM market entrants over the past few weeks. I have voiced some opinions in previous posts but have now started to capture a list of features that I believe represent the openings existing SIEM players have created in the market for these new vendors to emerge.
Before I outline what I think those features are, let me be clear: this is my list. I am aware that existing SIEM vendors will claim that they already do many of these things. All I will say is this: market churn and capital flow suggest that these capabilities are either not as mature or not as integrated as claimed.
And to the AI SOC companies and investors: be careful about the short-term problems your investments are solving. Yes, there is real traction with MSSPs that are overloaded with false positives. And yes, many will gladly pay to reduce alert workload by 80%. But in many cases, these problems are being addressed superficially. Make sure you audit the underlying approaches and verify that the foundational infrastructure is sound. Solving this problem on top of an existing detection infrastructure doesn’t solve the problem at the core, which is the detections themselves. We need to fix those with some of the suggestions below to not needing a top-layer, alert reducer.
Without further ado, here are the items I am tracking. I welcome other opinions and additions to the list (no guarantee I will include them). Over the coming weeks, I will also try to rate some of the players across these categories to enable comparison. I could use help with that. Ping me.
A. DATA & CONTROL PLANE ARCHITECTURE
Federation – The ability to query and reason over data where it lives, without forced centralization. (Another post following here at some point about the limitations of federation).
Data PipelineOptimization – Dynamic ingestion pipelines that enrich, route, sample, and filter data based on use case, risk, and downstream value. Not static “send everything to the lake.”
Data Awareness – Understanding what data exists, what is missing, and what has silently degraded. The system must continuously reason about its own observability.
Performance as a First-Class Constraint – Fast joins and low-latency queries across all relevant data. Real-time rule execution at scale. This is not about basic scalability, but about maintaining predictable performance as rule count and complexity increase, without simply throwing more compute at the problem.
Modern AI Integration – The ability to integrate with emerging architectural patterns and frameworks, including MCP servers, vector stores, and related systems.
B. DETECTION & LEARNING SYSTEMS
Hypothesis-Driven Hunting – Hunting should start with explicit hypotheses, not ad-hoc queries. These hypotheses should evolve, fork, and self-update based on outcomes. Agents swarms anyone?
Automated Detection Tuning (Closed Loop) – Detections must evaluate their precision and recall over time. False positives and false negatives are signals. Humans stay in the loop, but are not the tuning engine. This also helps separate the detection engineering from the tuning that should be done by analysts.
Environment-Adaptive Detections – Rules and models must adapt automatically to the specific environment, business processes, and user behavior and analyst feedback. Generic detections are table stakes.
Detection Lineage and Memory – The system must remember why a detection exists, how it has changed, and what outcomes it has historically produced.
C. ENTITY-CENTRIC RISK & CONTEXT
Asset Awareness – Effective protection and detection start with understanding what is being protected. Entity visibility is foundational: who owns this entity, what does it do, and which business processes does it support?
Real-Time Entity Risk Scoring – Each entity has a continuously updated risk score driven by behavior, exposure, and contextual signals.
Entity Risk Context – Risk is not a number. It is a set of properties that help explain the risk and provide context for decision making.
Business Context Integration – Entities must be tied to business processes, ownership, and criticality, and this context must inform alert generation and prioritization. Some people have started calling this the Context Graph.
D. OPERATIONAL REALITY (SOC, MSSP, ENFORCEMENT)
Simple QueryInterface: Support for both natural language and structured query languages (such as KQL). Analysts need both.
Alert Triage Automation – Using ‘advanced’ context to tune detections. Ideally we have business context available to continuously improve our detections.
Blindspot Detection – The system must actively identify where detections cannot exist due to missing or degraded logs or logging configurations. This includes making sure that log sources are actually staying up and keep reporting what they have to.
Real-Time Readiness for Enforcement – We need our systems to become preventative. Therefore, its risk model must operate in near real time. Attackers are acting too fast.
A Few Additional Comments for Context
This is not meant to be a SIEM RFP. I am intentionally not listing table-stakes capabilities such as basic scalability, data source support, or baseline detection depth.
This list is less about features than about where intelligence and control actually live in the system. I am also not being prescriptive on how these features are built. Many of them can benefit from AI / LLM / ML approaches and, in fact, should be using them.
Look at the list, then look at your AI SOC platform of choice. How much of the above does it truly cover?
If you are evaluating an AI SOC platform and most of its value proposition lives above alerts rather than below them, you should be skeptical.