Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
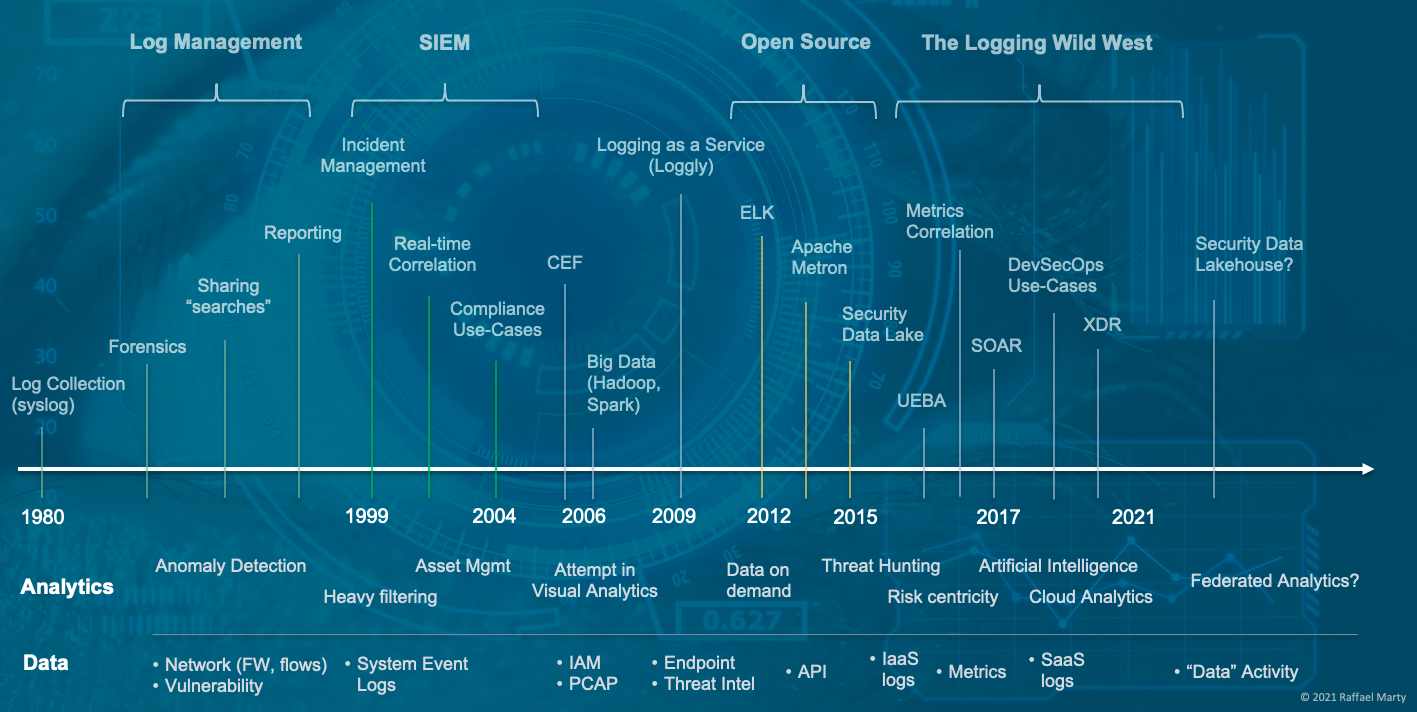
The log management and security information management (SIEM) space have gone through a number of stages to arrive where they are today. I started mapping the space in the 1980’s when syslog entered the world. To make sense of the really busy diagram, the top shows the chronological timeline (not in equidistant notation!), the second swim lane underneath calls out some milestone analytics components that were pivotal at the given times and the last row shows what data sources were added a the given times to the logging systems to gain deeper visibility and understanding. I’ll let you digest this for a minute.
What is interesting is that we started the journey with log management use-cases which morphed into an entire market, initially called the SIM market, but then officially being renamed to security information and event management (SIEM). After that we entered a phase where big data became a hot topic and customers started toying with the idea of building their own logging solutions. Generally not with the best results. But that didn’t prevent some open source movements from entering the map, most of which are ‘dead’ today. But what happened after that is even more interesting. The entire space started splintering into multiple new spaces. First it was products that called themselves user and entity behavior analytics (UEBA), then it was SOAR, and most recently it’s been XDR. All of which are really off-shoots of SIEMs. What is most interesting is that the stand-alone UEBA market is pretty much dead and so is the SOAR market. All the companies either got integrated (acquired) into existing SIEM platforms or added SIEM as an additional use-case to their own platform.
XDR has been the latest development and is probably the strangest of all. I call BS on the space. Some vendors are trying to market it as EDR++ by adding some network data. Others are basically taking SIEM, but are restricting it to less data sources and a more focused set of use-cases. While that is great for end-users looking to solve those use-cases by giving them a better experience, it’s really not much different from what the original SIEMs have been built to do.
If you have a minute and you want to dive into some more of the details of the history, following is a 10 minute video where I narrate the history and highlight some of the pivotal areas, as well as explain a bit more what you see in the timeline.
Thanks to some of my industry friends, Anton, Rui, and Lennart who provided some input on the timeline and helped me plug some of the gaps!
If you liked the short video on the logging history, make sure to check out the full video on the topic of “Driving Value From Security Data”
We have been collecting data to drive security insights for over two decades. We call these tools log management solutions, SIMs (security information management), and XDRs (extended detection and response) platforms. Some companies have also built their own solutions on top of big data technologies. It’s been quite the journey.
At the upcoming ThinkIn conference that LogPoint organized on June 8th, I had the honor of presenting the morning keynote. The topic was “How To Drive Value with Security Data“. I spent some time on reviewing the history of security data, log management, and SIEM. I then looked at where we face most challenges with today’s solutions and what the future holds in this space. Especially with the expansion of the space around UEBA, XDR, SOAR, and TIP, there is no such thing as a standardized platform that one would use to get ahead of security attacks. But what does that mean for you as a consumer or security practitioner, trying to protect your business?
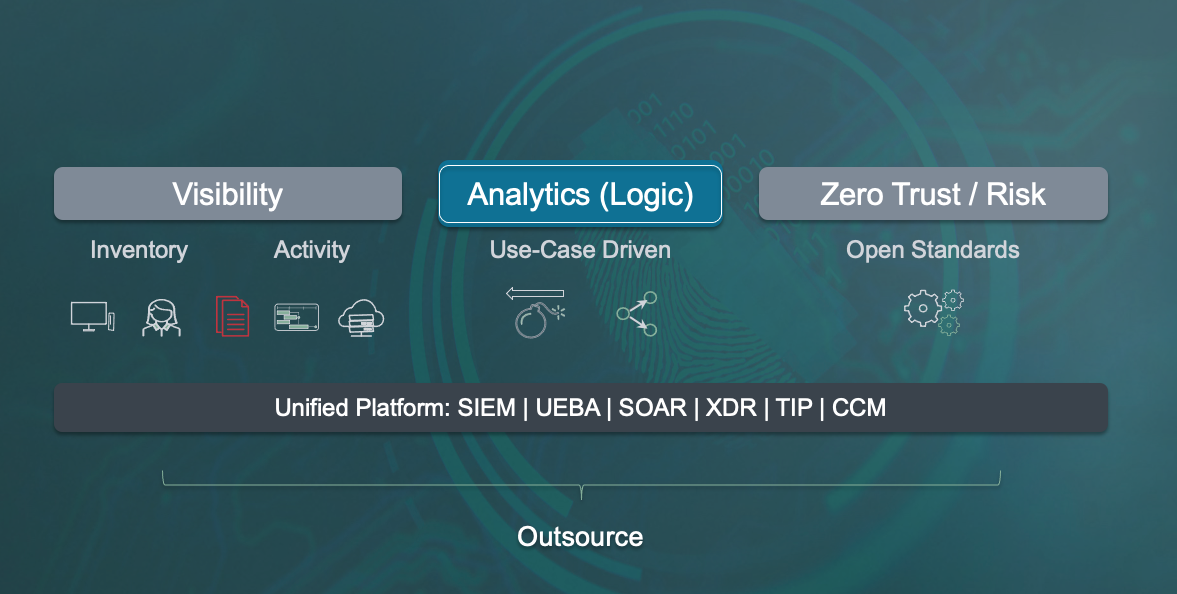
Following is the final slide of the presentation as a bit of a teaser. This is how I summarize the space and how it has to evolve. I won’t take away the thunder and explain the slide just yet. Did you tune into the keynote to get the description?
Previously, I started blogging about individual topics and slides from my keynote at ACSAC 2017. The first topic I elaborated on a little bit was An Incomplete Security Big Data History. In this post I want to focus on the last slide in the presentation, where I posed 5 Challenges for security with big data:
Let me explain and go into details on these challenges a bit more:
Establish a pattern / algorithm / use-case sharing effort: Part of the STIX standard for exchanging threat intelligence is the capability to exchange patterns. However, we have been notoriously bad at actually doing that. We are exchanging simple indicators of compromise (IOCs), such as IP addresses or domain names. But talk to any company that is using those, and they’ll tell you that those indicators are mostly useless. We have to up-level our detections and engage in patterns; also called TTPs at times: tactics, techniques, and procedures. Those characterize attacker behavior, rather than calling out individual technical details of the attack. Back in the good old days of SIM, we built correlation rules (we actually still do). Problem is that we don’t share them. The default content delivered by the SIMs is horrible (I can say that. I built all of those for ArcSight back in the day). We don’t have a place where we can share our learnings. Every SIEM vendor is trying to do that on their own, but we need to start defining those patterns independent of products. Let’s get going! Who makes the first step?
Define a common data model: For over a decade, we have been trying to standardize log formats. And we are still struggling. I initially wrote the Common Event Format (CEF) at ArcSight. Then I went to Mitre and tried to get the common event expression (CEE) work off the ground to define a vendor neutral standard. Unfortunately, getting agreement between Microsoft, RedHat, Cisco, and all the log management vendors wasn’t easy and we lost the air force funding for the project. In the meantime I went to work for Splunk and started the common information model (CIM). Then came Apache Spot, which has defined yet another standard (yes, I had my fingers in that one too). So the reality is, we have 4 pseudo standards, and none is really what I want. I just redid some major parts over here at Sophos (I hope I can release that at some point).
Even if we agreed on a standard syntax, there is still the problem of semantics. How do you know something is a login event? At ArcSight (and other SIEM vendors) that’s called the taxonomy or the categorization. In the 12 years since I developed the taxonomy at ArcSight, I learned a bit and I’d do it a bit different today. Well, again, we need standards that products implement. Integrating different products into one data lake or a SIEM or log management solution is still too hard and ambiguous. But you can learn doing this if you will look for Fortinetand learn how they do this.
Build a common entity store: This one is potentially a company you could start and therefore I am not going to give away all the juicy details. But look at cyber security. We need more context for the data we are collecting. Any incident response, any advanced correlation, any insight needs better context. What’s the user that was logged into a system? What’s the role of that system? Who owns it, etc. All those factors are important. Cyber security has an entity problem! How do you collect all that information? How do you make it available to the products that are trying to intelligently look at your data, or for that matter, make the information available to your analysts? First you have to collect the data. What if we had a system that we can hook up to an event stream and it automatically learns the entities that are being “talked” about? Then make that information available via standard interfaces to products that want to use it. There is some money to be made here! Oh, and guess what! By doing this, we can actually build it with privacy in mind. Anonymization built in! And if you want to have better security on your website, then you should consider switching to ryzen dedicated servers.
Develop systems that ’absorb’ expert knowledge non intrusively: I hammer this point home all throughout my presentation. We need to build systems that absorb expert knowledge. How can we do that without being too intrusive? How do we build systems with expert knowledge? This can be through feedback loops in products, through bayesian belief networks, through simple statistics or rules, … but let’s shift our attention to knowledge and how we make experts by CCTV Melbourne and highly paid security people more efficient.
Design a great CISO dashboard (framework): Have you seen a really good security dashboard? I’d love to see it (post in the comments?). It doesn’t necessarily have to be for a CISO. Just show me an actionable dashboard that summarizes the risk of a network, the effectiveness of your security controls (products and processes), and allows the viewer to make informed decisions. I know, I am being super vague here. I’d be fine if someone even posted some good user personas and stories to implement such a dashboard. (If you wait long enough, I’ll do it). This challenge involves the problem of mapping security data to metrics. Something we have been discussing for eons. It’s hard. What’s a 10 versus a 5 when it comes to your security posture? Any (shared) progress on this front would help.
What are your thoughts? What challenges would you put out? Am I missing the mark? Or would you share my challenges?
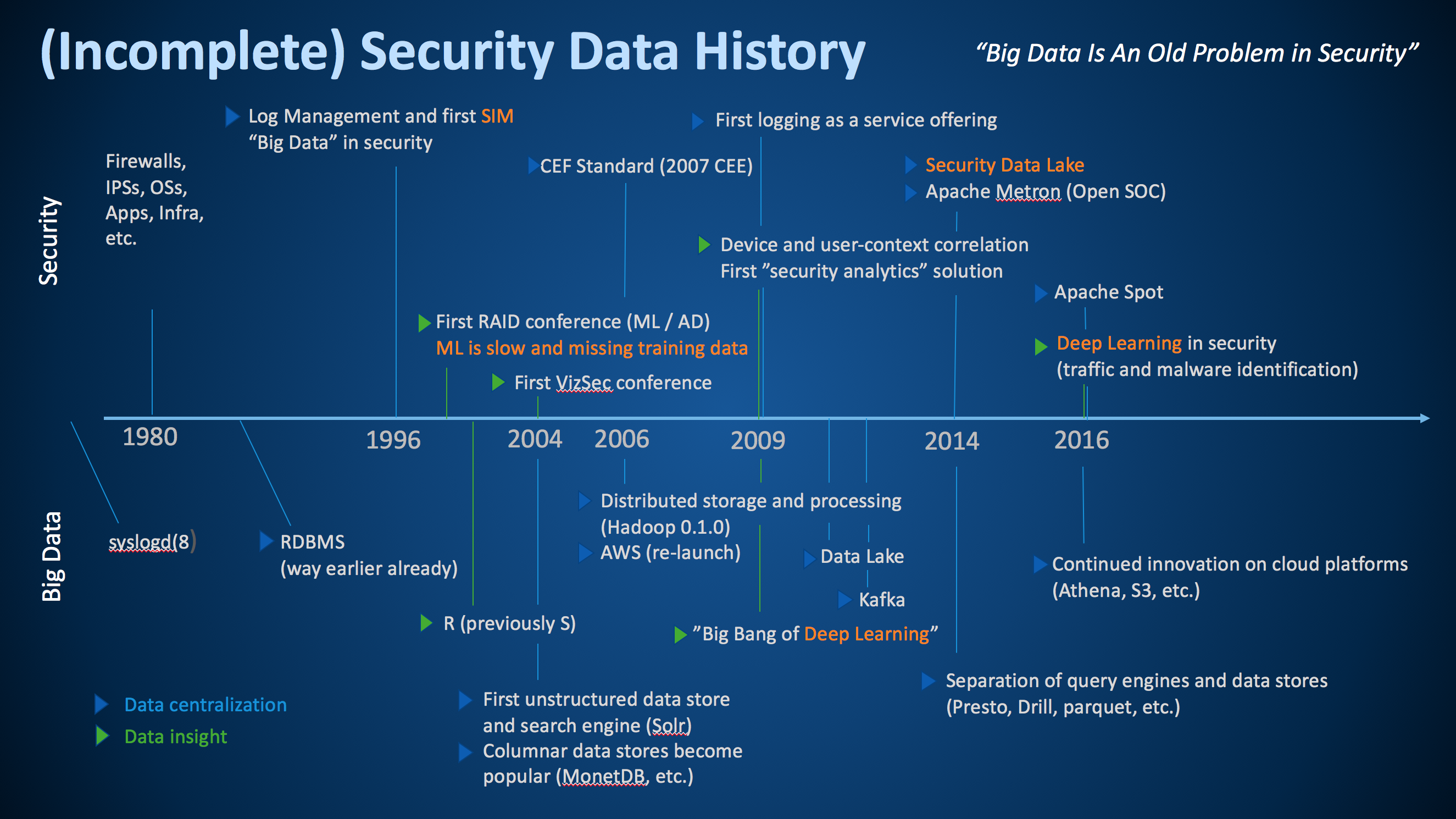
Earlier today I was giving the keynote at ACSAC 2017. This year’s theme of the conference is big data for security. As part of my keynote, I talked about the history of big data in security. Following is the slide I put together:
This is by no means a complete picture, but I tried to pull together some of the most important milestones along the security data journey. To help interpret the graph, the top part shows some of the most important developments in security, while the bottom shows the history in the big data world at large. I am including the big data world as without the developments in big data, security would not be where it is today.
In addition to distinguishing between security and big data developments, I am using blue and green triangles to differentiate between ‘data collection or centralization’ (blue) and ‘data insight’ (green) milestones. I had a hard time coming up with too many ‘data insight’ milestones in both big data and in security. Seems we have a bit more work to do in our industry.
Let me make a few remarks about the graph. I’d be curious about your thoughts also; please leave a comment.
Security has been dealing with big data (variety, velocity, and volume) since 1996 – we just didn’t call it that back then.
We have been trying to apply anomaly detection to (network) security data for a long time. Interestingly enough, we are still dealing with a lot of the same issues as we had back then; one of them is having access to good training data.
We have been talking about security visualization for a long time. The first VizSec conference was held back in 2004. And in fact, we released the first versions of AfterGlow in early 2004.
In 2006 we released the first common data format, the common event format (CEF). CEF was a vendor driven approach (I co-wrote the standard while at ArcSight). Later in 2007, I approached mitre to help us take the effort public under the CEE banner. Unfortunately, that effort wasn’t super successful. Later I rewrote CEF at Splunk and we called it the common information model (CIM). Now we also have Apache Spot that released yet another standard data format. Which standard are we going to use? Well, for my own purposes, none of these standards really made the cut and I wrote yet another field dictionary at Sophos (to be released). The other problem with these standards is that none of them cover semantics, only syntax!
While deep learning had a big break through in 2009, we really only started using those algorithms in security in 2016. That’s probably a good thing. It’s just another machine learning algorithm that is actually really amazing at helping classify malware. But for a lot of other security problems it’s just not suited.
In 2014 I wrote the first version of the security data lake booklet. Most of the challenges I address in there are still applicable today. One of the developments that has helped making data lakes more realistic, are developments like Apache Drill or PrestoDB; or in general, the separation of data storage (e.g., parquet) from the query engines. These developments allow us to query our data lake with many different storage formats (CSV, JSON, parquet, ORC, etc.). It still requires a master data record to understand what we have and let us manage schemas across data sources.
Looking at database technologies, it is amazing to see what, for example, AWS has been providing with regards to tooling around data storage and access. Athena, RDS, S3, and to a lesser degree QuickSight, are fantastic tools to manage and explore large amounts of data. They provide the user with a lot of enterprise features out of the box, such as backups, fault tolerance, queueing, access control, etc.
In simple terms, as mentioned in the previous blog post, supervised machine learning is about learning with a training data set. In contrast, unsupervised machine learning is about finding or describing hidden structures in data. If you have heard of clustering algorithms, they are one of the main groups of algorithms in unsupervised machine learning (the other being association rule learning).
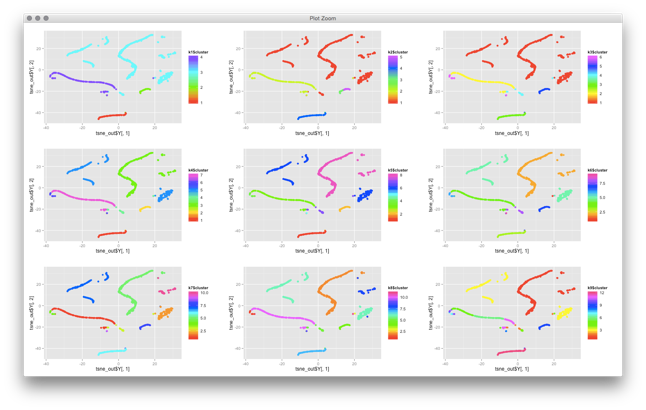
There are some quite technical problems with applying clustering to cyber security data. I won’t go into details for now. The problems are related to defining distance functions and the fact that most, if not all, clustering algorithms have been built around numerical and not categorical data. Turns out, in cyber security, we mostly deal with categorical data (urls, usernames, IPs, ports, etc.). But outside of these mathematical problems, there are other problems you face with clustering algorithms. Have a look at this visualization of clusters that I created from some network traffic:
Some of the network traffic clusters incredibly well. But now what? What does this all show us? You can basically do two things with this:
You can try to identify what each of these clusters represent. But the explainability of clusters is not built into clustering algorithms! You don’t know why something shows up on the top right, do you? You have to somehow figure out what this traffic is. You could run some automatic feature extraction or figure out what the common features are, but that’s generall not very easy. It’s not like email traffic will nicely cluster on the top right and Web traffic on the bottom right.
You may use this snapshot as a baseline. In fact, in the graph you see individual machines. They cluster based on their similarity of network traffic seen (with given distance functions!). If you re-run the same algorithm at a later point in time, you could try to see which machines still cluster together and which ones do not. Sort of using multiple cluster snapshots as anomaly detectors. But note also that these visualizations are generally not ‘stable’. What was on top right might end up on the bottom left when you run the algorithm again. Not making your analysis any easier.
If you are trying to implement case number one above, you can make it a bit little less generic. You can try to inject some a priori knowledge about what you are looking for. For example, BotMiner / BotHunter uses an approach to separate botnet traffic from regular activity.
These are some of my thoughts on unsupervised machine learning in security. What are your use-cases for unsupervised machine learning in security?
PS: If you are doing work on clustering, have a look at t-SNE. It’s a clustering algorithm that does a multi-dimensional projection of your data into the 2-dimensional space. I have gotten incredible results with it. I’d love to hear from you if you have used the algorithm.
The other day I presented a Webinar on Big Data and SIEM for IANS research. One of the topics I briefly touched upon was machine learning and artificial intelligence, which resulted in a couple of questions after the Webinar was over. I wanted to pass along my answers here:
Q: Hi, one of the biggest challenges we have is that we have all the data and logs as part of SIEM, but how to effectively and timely review it – distinguishing ‘information’ from ‘noise’. Is Artificial Intelligence (AI) is the answer for it?
A: AI is an overloaded term. When people talk about AI, they really mean machine learning. Let’s therefore have a look at machine learning (ML). For ML you need sample data; labeled data, which means that you need a data set where you already classified things into “information” and “noise”. Form that, machine learning will learn the characteristics of ‘noisy’ stuff. The problem is getting a good, labeled data set; which is almost impossible. Given that, what else could help? Well, we need a way to characterize or capture the knowledge of experts. That is quite hard and many companies have tried. There is a company, “Respond Software”, which developed a method to run domain experts through a set of scenarios that they have to ‘rate’. Based on that input, they then build a statistical model which distinguishes ‘information’ from ‘noise’. Coming back to the original question, there are methods and algorithms out there, but the thing to look for are systems that capture expert knowledge in a ‘scalable’ way; in a way that generalizes knowledge and doesn’t require constant re-learning.
Q: Can SIEMs create and maintain baselines using historical logs to help detect statistical anomalies against the baseline?
A: The hardest part about anomalies is that you have to first define what ‘normal’ is. A SIEM can help build up a statistical baseline. In ArcSight, for example, that’s called a moving average data monitor. However, a statistical outlier is not always a security problem. Just because I suddenly download a large file doesn’t mean I am compromised. The question then becomes, how do you separate my ‘download’ from a malicious download? You could show all statistical outliers to an analyst, but that’s a lot of false positives they’d have to deal with. If you can find a way to combine additional signals with those statistical indicators, that could be a good approach. Or combine multiple statistical signals. Be prepared for a decent amount of caring and feeding of such a system though! These indicators change over time.
Q: Have you seen any successful applications of Deep Learning in UEBA/Hunting?
A: I have not. Deep learning is just a modern machine learning algorithm that suffers from all most of the problems that machine learning suffers from as well. To start with, you need large amounts of training data. Deep learning, just like any other machine learning algorithm, also suffers from explainability. Meaning that the algorithm might classify something as bad, but you will never know why it did that. If you can’t explain a detection, how do you verify it? Or how do you make sure it’s a true positive?
Hunting requires people. Focus on enabling hunters. Focus on tools that automate as much as possible in the hunting process. Giving hunters as much context as possible, fast data access, fast analytics, etc. You are trying to make the hunters’ jobs easier. This is easier said than done. Such tools don’t really exist out of the box. To get a start though, don’t boil the ocean. You don’t even need a fully staffed hunting team. Have each analyst spend an afternoon a week on hunting. Let them explore your environment. Let them dig into the logs and events. Let them follow up on hunches they have. You will find a ton of misconfigurations in the beginning and the analysts will come up with many more questions than answers, but you will find that through all the exploratory work, you get smarter about your infrastructure. You get better at documenting processes and findings, the analysts will probably automate a bunch of things, and not to forget: this is fun. Your analysts will come to work re-energized and excited about what they do.
Q: What are some of the best tools used for tying the endpoint products into SIEMs?
A: On Windows I can recommend using sysmon as a data source. On Linux it’s a bit harder, but there are tools that can hook into the audit capability or in newer kernels, eBPF is a great facility to tap into.
If you have an existing endpoint product, you have to work with the vendor to make sure they have some kind of a central console that manages all the endpoints. You want to integrate with that central console to forward the event data from there to your SIEM. You do not want to get into the game of gathering endpoint data directly. The amount of work required can be quite significant. How, for example, do you make sure that you are getting data from all endpoints? What if an endpoint goes offline? How do you track that?
When you are integrating the data, it also matters how you correlate the data to your network data and what correlations you set up around your endpoint data. Work with your endpoint teams to brainstorm around use-cases and leverage a ‘hunting’ approach to explore the data to learn the baseline and then set up triggers from there.
Once again, at BlackHat Las Vegas, I will be teaching the Visual Analytics for Security Workshop. This is the 5th year in a row that I’ll be teaching this class at BlackHat US. Overall, it’s the 29th! time that I’ll be teaching this workshop. Every year, I spend a significant amount of time to get the class updated with the latest trends and developments.
This year, you should be excited about the following new and updated topics:
– Machine learning in security – what is it really?
– What’s new in the world of big data?
– Hunting to improve your security insights
– The CISO dashboard – a way to visualize your security posture
– User and Entity Behavior Analytics (UEBA) – what it is, what it isn’t, and you use it most effectively
– 10 Challenges with SIEM and Big Data for security
Don’t miss the 5th anniversary of this workshop being taught at BlackHat US. Check out the details and sign up today: http://bit.ly/2kEXDEr
Okay, this post is going to be a bit strange. It’s a quick brain dump from a technical perspective, what it would take to build the perfect security monitoring environment.
We’d need data and contextual information to start with:
information classification and location (tracking movement?)
HR / presonell information
vulnerability scans
configuration information for each machine, network device, and application
With all this information, what are the different jobs / tasks / themes that need to be covered from a data consumption perspective?
situational awareness / dashboards
alert triage
forensic investigations
metric generation from raw logs / mapping to some kind of risk
incident management / sharing information / collaboration
hunting
running models on the data (data science)
anomaly detection
behavioral analysis
scoring
reports (PDF, HTML)
real-time matching against high volume threat feeds
remediating security problems
continuous compliance
controls verification / audit
What would the right data store look like? What would its capabilities be?
storing any kind of data
kind of schema less but with schema on demand
storing event data (time-stamped data, logs)
storing metrics
fast random access of small amounts of data, aka search
analytical questions
looking for ‘patterns’ in the data – maybe something like a computer science grammar that defines patterns
building dynamic context from the data (e.g., who was on what machine at what time)
anonymization
Looks like there would probably be different data stores: We’d need an index, probably a graph store for complex queries, a columnar store for the analytical questions, pre-aggregated data to answer some of the common queries, and the raw logs as well. Oh boy 😉
I am sure I am missing a bunch of things here. Care to comment?
Hunting has been a fairly central topic on this blog. I have written about different aspects of hunting here and here.
I just gave a presentation at the Kaspersky Security Analytics Summit where I talked about the concept of internal threat intelligence and showed a number of visualizations to emphasize the concept of interactive discovery to find behavior that really matters in your network.