
Earlier today I was giving the keynote at ACSAC 2017. This year’s theme of the conference is big data for security. As part of my keynote, I talked about the history of big data in security. Following is the slide I put together:
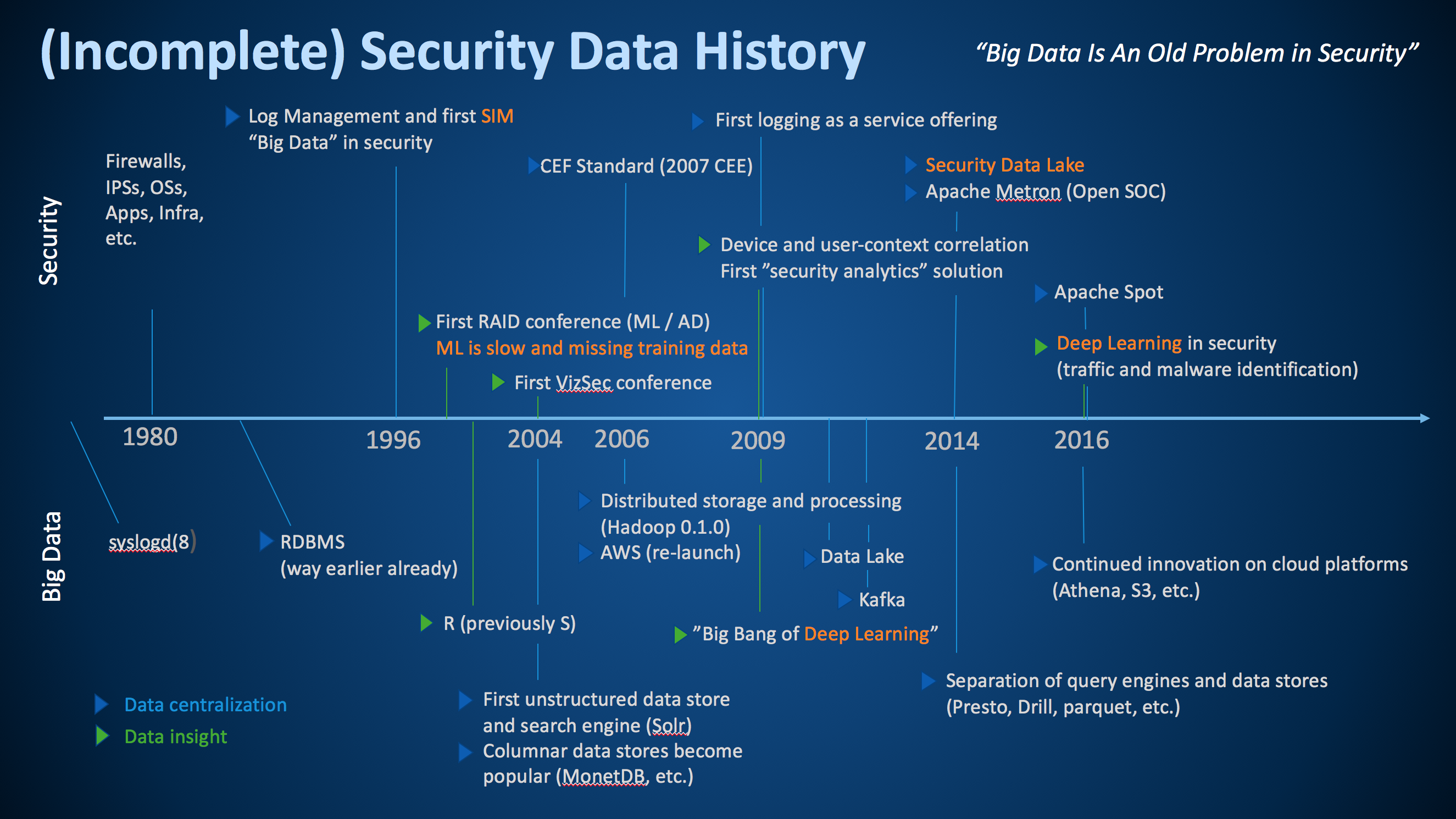
This is by no means a complete picture, but I tried to pull together some of the most important milestones along the security data journey. To help interpret the graph, the top part shows some of the most important developments in security, while the bottom shows the history in the big data world at large. I am including the big data world as without the developments in big data, security would not be where it is today.
In addition to distinguishing between security and big data developments, I am using blue and green triangles to differentiate between ‘data collection or centralization’ (blue) and ‘data insight’ (green) milestones. I had a hard time coming up with too many ‘data insight’ milestones in both big data and in security. Seems we have a bit more work to do in our industry.
Let me make a few remarks about the graph. I’d be curious about your thoughts also; please leave a comment.
- Security has been dealing with big data (variety, velocity, and volume) since 1996 – we just didn’t call it that back then.
- We have been trying to apply anomaly detection to (network) security data for a long time. Interestingly enough, we are still dealing with a lot of the same issues as we had back then; one of them is having access to good training data.
- We have been talking about security visualization for a long time. The first VizSec conference was held back in 2004. And in fact, we released the first versions of AfterGlow in early 2004.
- In 2006 we released the first common data format, the common event format (CEF). CEF was a vendor driven approach (I co-wrote the standard while at ArcSight). Later in 2007, I approached mitre to help us take the effort public under the CEE banner. Unfortunately, that effort wasn’t super successful. Later I rewrote CEF at Splunk and we called it the common information model (CIM). Now we also have Apache Spot that released yet another standard data format. Which standard are we going to use? Well, for my own purposes, none of these standards really made the cut and I wrote yet another field dictionary at Sophos (to be released). The other problem with these standards is that none of them cover semantics, only syntax!
- While deep learning had a big break through in 2009, we really only started using those algorithms in security in 2016. That’s probably a good thing. It’s just another machine learning algorithm that is actually really amazing at helping classify malware. But for a lot of other security problems it’s just not suited.
- In 2014 I wrote the first version of the security data lake booklet. Most of the challenges I address in there are still applicable today. One of the developments that has helped making data lakes more realistic, are developments like Apache Drill or PrestoDB; or in general, the separation of data storage (e.g., parquet) from the query engines. These developments allow us to query our data lake with many different storage formats (CSV, JSON, parquet, ORC, etc.). It still requires a master data record to understand what we have and let us manage schemas across data sources.
- Looking at database technologies, it is amazing to see what, for example, AWS has been providing with regards to tooling around data storage and access. Athena, RDS, S3, and to a lesser degree QuickSight, are fantastic tools to manage and explore large amounts of data. They provide the user with a lot of enterprise features out of the box, such as backups, fault tolerance, queueing, access control, etc.
What major milestones am I missing?