Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
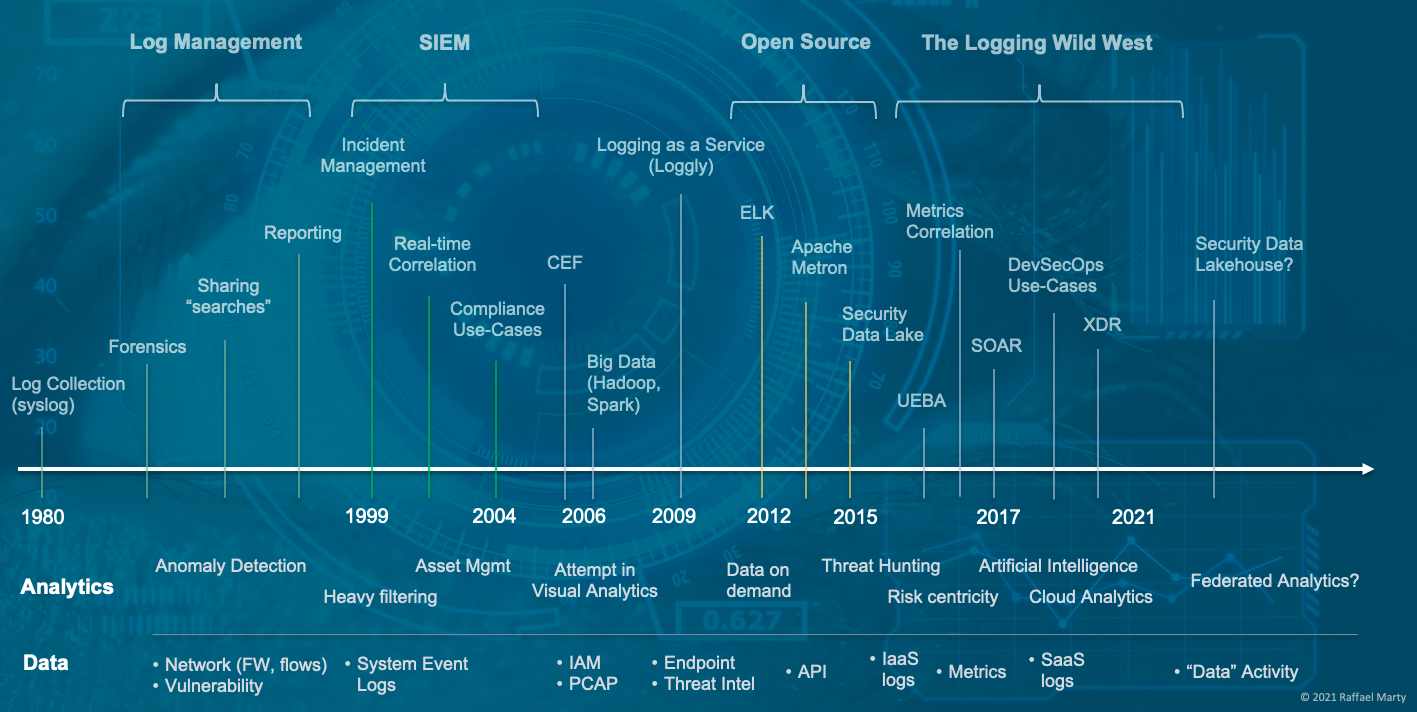
The log management and security information management (SIEM) space have gone through a number of stages to arrive where they are today. I started mapping the space in the 1980’s when syslog entered the world. To make sense of the really busy diagram, the top shows the chronological timeline (not in equidistant notation!), the second swim lane underneath calls out some milestone analytics components that were pivotal at the given times and the last row shows what data sources were added a the given times to the logging systems to gain deeper visibility and understanding. I’ll let you digest this for a minute.
What is interesting is that we started the journey with log management use-cases which morphed into an entire market, initially called the SIM market, but then officially being renamed to security information and event management (SIEM). After that we entered a phase where big data became a hot topic and customers started toying with the idea of building their own logging solutions. Generally not with the best results. But that didn’t prevent some open source movements from entering the map, most of which are ‘dead’ today. But what happened after that is even more interesting. The entire space started splintering into multiple new spaces. First it was products that called themselves user and entity behavior analytics (UEBA), then it was SOAR, and most recently it’s been XDR. All of which are really off-shoots of SIEMs. What is most interesting is that the stand-alone UEBA market is pretty much dead and so is the SOAR market. All the companies either got integrated (acquired) into existing SIEM platforms or added SIEM as an additional use-case to their own platform.
XDR has been the latest development and is probably the strangest of all. I call BS on the space. Some vendors are trying to market it as EDR++ by adding some network data. Others are basically taking SIEM, but are restricting it to less data sources and a more focused set of use-cases. While that is great for end-users looking to solve those use-cases by giving them a better experience, it’s really not much different from what the original SIEMs have been built to do.
If you have a minute and you want to dive into some more of the details of the history, following is a 10 minute video where I narrate the history and highlight some of the pivotal areas, as well as explain a bit more what you see in the timeline.
Thanks to some of my industry friends, Anton, Rui, and Lennart who provided some input on the timeline and helped me plug some of the gaps!
If you liked the short video on the logging history, make sure to check out the full video on the topic of “Driving Value From Security Data”
We have been collecting data to drive security insights for over two decades. We call these tools log management solutions, SIMs (security information management), and XDRs (extended detection and response) platforms. Some companies have also built their own solutions on top of big data technologies. It’s been quite the journey.
At the upcoming ThinkIn conference that LogPoint organized on June 8th, I had the honor of presenting the morning keynote. The topic was “How To Drive Value with Security Data“. I spent some time on reviewing the history of security data, log management, and SIEM. I then looked at where we face most challenges with today’s solutions and what the future holds in this space. Especially with the expansion of the space around UEBA, XDR, SOAR, and TIP, there is no such thing as a standardized platform that one would use to get ahead of security attacks. But what does that mean for you as a consumer or security practitioner, trying to protect your business?
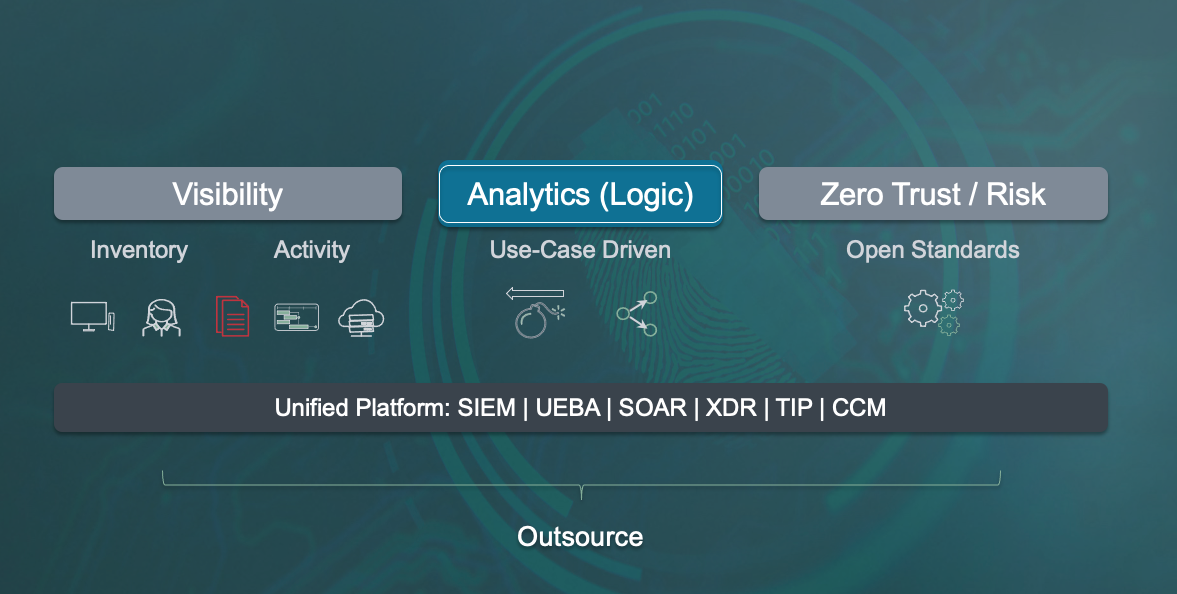
Following is the final slide of the presentation as a bit of a teaser. This is how I summarize the space and how it has to evolve. I won’t take away the thunder and explain the slide just yet. Did you tune into the keynote to get the description?
Once again, at BlackHat Las Vegas, I will be teaching the Visual Analytics for Security Workshop. This is the 5th year in a row that I’ll be teaching this class at BlackHat US. Overall, it’s the 29th! time that I’ll be teaching this workshop. Every year, I spend a significant amount of time to get the class updated with the latest trends and developments.
This year, you should be excited about the following new and updated topics:
– Machine learning in security – what is it really?
– What’s new in the world of big data?
– Hunting to improve your security insights
– The CISO dashboard – a way to visualize your security posture
– User and Entity Behavior Analytics (UEBA) – what it is, what it isn’t, and you use it most effectively
– 10 Challenges with SIEM and Big Data for security
Don’t miss the 5th anniversary of this workshop being taught at BlackHat US. Check out the details and sign up today: http://bit.ly/2kEXDEr
Okay, this post is going to be a bit strange. It’s a quick brain dump from a technical perspective, what it would take to build the perfect security monitoring environment.
We’d need data and contextual information to start with:
information classification and location (tracking movement?)
HR / presonell information
vulnerability scans
configuration information for each machine, network device, and application
With all this information, what are the different jobs / tasks / themes that need to be covered from a data consumption perspective?
situational awareness / dashboards
alert triage
forensic investigations
metric generation from raw logs / mapping to some kind of risk
incident management / sharing information / collaboration
hunting
running models on the data (data science)
anomaly detection
behavioral analysis
scoring
reports (PDF, HTML)
real-time matching against high volume threat feeds
remediating security problems
continuous compliance
controls verification / audit
What would the right data store look like? What would its capabilities be?
storing any kind of data
kind of schema less but with schema on demand
storing event data (time-stamped data, logs)
storing metrics
fast random access of small amounts of data, aka search
analytical questions
looking for ‘patterns’ in the data – maybe something like a computer science grammar that defines patterns
building dynamic context from the data (e.g., who was on what machine at what time)
anonymization
Looks like there would probably be different data stores: We’d need an index, probably a graph store for complex queries, a columnar store for the analytical questions, pre-aggregated data to answer some of the common queries, and the raw logs as well. Oh boy 😉
I am sure I am missing a bunch of things here. Care to comment?
Hunting has been a fairly central topic on this blog. I have written about different aspects of hunting here and here.
I just gave a presentation at the Kaspersky Security Analytics Summit where I talked about the concept of internal threat intelligence and showed a number of visualizations to emphasize the concept of interactive discovery to find behavior that really matters in your network.
VCs pay attention: There is an opportunity here, but it is going to be risky 😉 If you want to fund this, let me know.
In short: We need a company that builds and supports the data processing backend for all security products. Make it open source / free. And I don’t think this will be Cloudera. It’s too security specific. But they might have money to fund it? Tom?
I have had my frustrations with the security industry lately. Companies are not building products anymore, but features. Look at the security industry: You have a tool that does behavioral modeling for network traffic. You have a tool that does scoring of users based on information they extract from active directory. Yet another tool does the same for Linux systems and the next company does the same thing for the financial industry. Are you kidding me?
If you are a CISO right now, I don’t envy you. You have to a) figure out what type of products to even put in your environment and b) determine how to operate those products. We are back at where we were about 15 years ago. You need a dozen consoles to gain an understanding of your overall security environment. No cross-correlation, just an oportunity to justify the investment into a dozen screens on each analysts’ desk. Can we really not do better?
One of the fundamental problems that we have is that every single product re-builds the exact same data stack. Data ingestion with parsing, data storage, analytics, etc. It’s exactly the same stack in every single product. And guess what; using the different products, you have to feed all of them the exact same data. You end up collecting the same data multiple times.
We need someone – a company – to build the backend stack once and for all. It’s really clear at this point how to do that: Kafka -> Spark Streaming – Parquet and Cassandra – Spark SQL (maybe Impala). Throw some Esper in the mix, if you want to. Make the platform open so that everyone can plug in their own capabilities and we are done. Not rocket science. Addition: And it should be free / open source!
The hard part comes after. We need every (end-user) company out there to deploy this stack as their data pipeline and storage system (see Security Data Lake). Then, every product company needs to build their technology on top of this stack. That way, they don’t have to re-invent the wheel, companies don’t have to deploy dozens of products, and we can finally build decent product companies again that can focus on their core capabilities.
Now, who is going to fund the product company to build this? We don’t have time to go slow like Elastic in the case of ElasticSearch or RedHat for Linux. We need need this company now; a company that pulls together the right open source components, puts some glue between them, and offers services and maintenance.
Afterthought: Anyone feel like we are back in the year 2000? Isn’t this the exact same situation that the SIEMs were born out of? They promised to help with threat detection. Never delivered. Partly because of the technologies used (RDBMS). Partly due to the closeness of the architecture. Partly due to the fact that we thought we could come up with some formula that computes a priority for each event. Then look at priority 10 events and you are secure. Naive; or just inexperienced. (I am simplifying, but the correlation part is just an add-on to help find important events). If it weren’t for regulations and compliance use-cases, we wouldn’t even speak of SIEMs anymore. It’s time to rebuild this thing the right way. Let’s learn from our mistakes (and don’t get me started what all we have and are still doing wrong in our SIEMs [and those new “feature” products out there]).
Hunting in your security data is the process of using exploratory methods to discover insights and hopefully finding attacks that have previously been concealed. Visualization greatly simplifies and makes the exploratory process more efficient.
In my previous post, I talked about SIEM use-cases. I outlined how I go about defining detection use-cases. It’s not a linear process and it’s not something that is the same for every company. That’s also a reason why I didn’t give you a list of use-cases to implement in your SIEM. There are guidelines, but in the end, you need to build a use-case repository unique to your organization. In this post we are going to explore a bit more what that means and how a ‘hunting‘ capability can help you with that.
There are three main approaches to implementing a use-case in a SIEM:
Rules: Some kind of deterministic set of conditions. For example: Find three consecutive failed logins between the same machines and using the same username.
Simple statistics: Leveraging simple statistical properties, such as standard deviations, means, medians, or correlation measures to characterize attacks or otherwise interesting behavior. A simple example would be to look at the volume of traffic between machines and finding instances where the volume deviates from the norm by more than two standard deviations.
Behavioral models: Often behavioral models are just slightly more complicated statistics. Scoring is often the bases of the models. The models often rely on classifications or regressions. On top of that you then define anomaly detectors that flag outliers. An example would be to look at the behavior of each user in your system. If their behavior changes, the model should flag that. Easier said than done.
I am not going into discussing how effective these above approaches are and what the issues are with them. Let’s just assume they are effective and easy to implement. [I can’t resist: On anomaly detection: Just answer me this: “What’s normal?” Oh, and don’t get lost in complicated data science. Experience shows that simple statistics mostly yield the best output.]
Let’s bring things back to visualization and see how that related to all of this. I like to split visualization into two areas:
Communication: This is where you leverage visualization to communicate some property of your data. You already know what you want the viewer to focus on. This is often closely tied to metrics that help abstract the underlying data into something that can be put into a dashboard. Dashboards are meant to help the viewer gain an overview of what is happening; the overall state. Only in some very limited cases will you be able to use dashboards to actually discover some novel insight into your data. That’s not their main purpose.
Exploration: What is my data about? This is literal exploration where one leverages visualization to dig into the data to quickly understand it. Generally we don’t know what we are going to find. We don’t know our data and want to understand it as quickly as possible. We want insights.
From a visualization standpoint the two are very different as well. Visually exploring data is done using more sophisticated visualizations, such as parallel coordinates, heatmaps, link graphs, etc. Sometimes a bar or a line chart might come in handy, but those are generally not “data-dense” enough. Following are a couple more points about exploratory visualizations:
It important to understand that these approaches need very powerful backends or data stores to drive the visualizations. This is not Excel!
Visualization is not enough. You also need a powerful way of translating your data into visualizations. Often this is simple aggregation, but in some cases, more sophisticated data mining comes in handy. Think clustering.
The exploratory process is all about finding unknowns. If you already knew what you are looking for, visualization might help you identify those instances quicker and easier, but generally you would leverage visualization to find the unknown unknowns. Once you identified them, you can then go ahead and implement those with one of the traditional approaches: rules, statistics, or behaviors in order to automate finding them in the future.
Some of the insights you will discover can’t be described in any of the above ways. The parameters are not clear or change ever so slightly. However, visually those outliers are quite apparent. In these cases, you should extend your analysis process to regularly have someone visualize the data to look for these instances.
You can absolutely try to explore your data without visualization. In some instances that might work out well. But careful; statistical summaries of your data will never tell you the full story (see Anscombe’s Quartet – the four data series all have the same statistical summaries, but looking at the visuals, each of them tells a different story).
In cyber security (or information security), we have started calling the exploratory process “Hunting“. This closes the loop to our SIEM use-cases. Hunting is used to discover and define new detection use-cases. I see security teams leverage hunting capabilities to do exactly that. Extending their threat intelligence capabilities to find the more sophisticated attackers that other tools wouldn’t be able to identify. Or maybe only partly, but then in concert with other data sources, they are able to create a better, more insightful picture.
In the context of hunting, a client lately asked the following questions: How do you measure the efficiency of your hunting team? How do you justify a hunting team opposite an ROI? And how do you assess the efficiency of analyst A versus analyst B? I gave them the following three answers:
When running any red-teaming approach, how quickly is your hunting team able to find the attacks? Are they quicker than your SOC team?
Are your hunters better than your IDS? Or are they finding issues that your IDS already flagged? (substitute IDS with any of your other detection mechanisms)
How many incidents are reported to you from outside the security group? Does your hunting team bring those numbers down? If your hunting team wasn’t in place, would that number be even higher?
For each incident that is reported external to your security team, assess whether the hunt team should have found them. If not, figure out how to enable them to do that in the future.
Unfortunately, there are no great hunting tools out there. Especially when it comes to leveraging visualization to do so. You will find people using some of the BI tools to visualize traffic, build Hadoop-based backends to support the data needs, etc. But in the end; these approaches don’t scale and won’t give you satisfying visualization and in turn insights. But that’s what pixlcloud‘s mission is. Get in touch!
Put your hunting experience, stories, challenges, and insights into the comments! I wanna hear from you!
As it happens, I do a lot of consulting for companies that have some kind of log management or SIEM solution deployed. Unfortunately, or maybe not really for me, most companies have a hard time figuring out what to do with their expensive toys. [It is a completely different topic what I think about the security monitoring / SIEM space in general – it’s quite broken.] But here are some tips that I share with companies that are trying to get more out of their SIEMs:
First and foremost, start with use-cases. Time and time again, I am on calls with companies and they are telling me that they have been onboarding data sources for the last 4 months. When I ask them what they are trying to do with them, it gets really quiet. Turns out that’s what they expected me to tell them. Well, that’s not how it works. You have to come up with the use-cases you want/need to implement yourself. I don’t know your specific environment, your security policy, or your threat profile. These are the factors that should drive your use-cases.
Second, focus on your assets / machines. Identify your most valuable assets – the high business impact (HBI) machines and network segments. Even just identifying them can be quite challenging. I can guarantee you though; the time is well spent. After all, you need to know what you are protecting.
Model a set of use-cases around your HBIs. Learn as much as you can about them: What software is running on them? What processes are running? What ports are open? And from a network point of view, what other machines are they communicating with? What internal machines have access to talk to them? Do they talk to the outside world? What machines? How may different ones? When? Use your imagination to come up with more use-cases. Monitor the machines for a week and start defining some policies / metrics that you can monitor. Keep adopting them over time.
Based on your use-cases, determine what data you need. You will be surprised what you learn. Your IDS logs might suddenly loose a lot of importance. But your authentication logs and network flows might come in pretty handy. Note how we turned things around; instead of having the data dictate our use-cases, we have the use-cases dictate what data we collect.
Next up, figure out how to actually implement your use-cases. Your SIEM is probably going to be the central point for most of the use-case implementations. However, it won’t be able to solve all of your use-cases. You might need some pretty specific tools to model user behavior, machine communications, etc. But also don’t give up too quickly. Your SIEM can do a lot; even initial machine profiling. Try to work with what you have.
Ideally you go through this process before you buy any products. To come up with a set of use-cases, involve your risk management people too. They can help you prioritize your efforts and probably have a number of use-cases they would like to see addressed as well. What I often do is organize a brainstorming session with many different stakeholders across different departments.
Here are some additional resources that might come in handy in your use-case development efforts:
Popular SIEM Starter Use Cases – This is a short list of use-cases you can work with. You will need to determine how exactly to collect the data that Anton is talking about in this blog post and how to actually implement the use-case, but the list is a great starting point.
AlienVault SIEM Use-Cases – Scroll down just a bit and you will see a list of SIEM use-cases. If you click on them, they will open up and show you some more details around how to implement them. Great list to get started.
SANS Critical Security Controls – While this is not specifically a list of SIEM use-cases, I like to use this list as a guide to explore SIEM use-cases. Go through the controls and identify which ones you care about and how you could map them to your SIEM.
NIST 800-53 – This is NIST’s control framework. Again, not directly a list of SIEM use-cases, but similar to the SANS list, a great place for inspiration, but also a nice framework to follow in order to make sure you cover the important use-cases. [When I was running the solution team at ArcSight, we implemented an entire solution (app) around the NIST framework.]
Interestingly enough, on most of my recent consulting calls and engagements around SIEM use-cases, I got asked about how to visualize the data in the SIEM to make it more tangible and actionable. Unfortunately, there is no tool out there that would let you do that out of the box. Not yet. Here are a couple of resources you can have a look at to get going though:
secviz.org is the community portal for security visualization
I sometimes use Gephi for network graph visualizations. The problem is that it is limited to only network graphs. Very quickly you will realize that it would be nice to have other, linked visualizations too. You are off in ‘do it yourself’ land.
There is also DAVIX which is a Linux distro for security visualization with a ton of visualization tools readily installed.
As announced in the previous blog post, I have been writing a paper about the security big data lake. A topic that starts coming up with more and more organizations lately. Unfortunately, there is a lot uncertainty around the term so I decided to put some structure to the discussion.
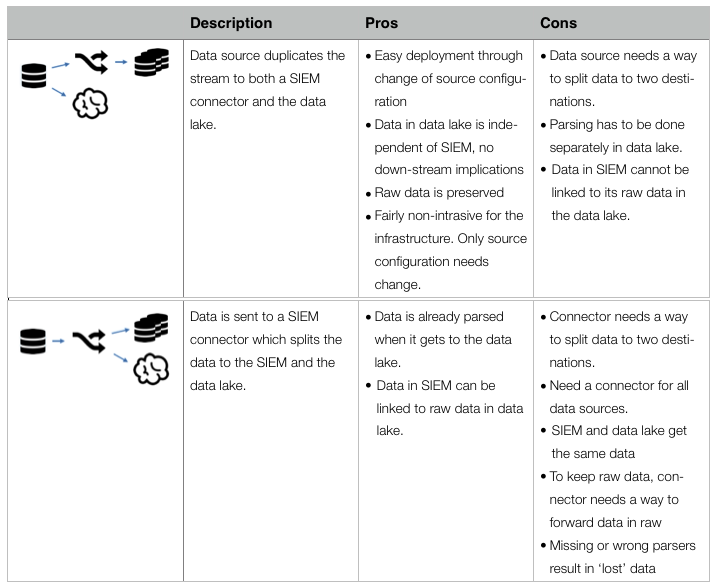
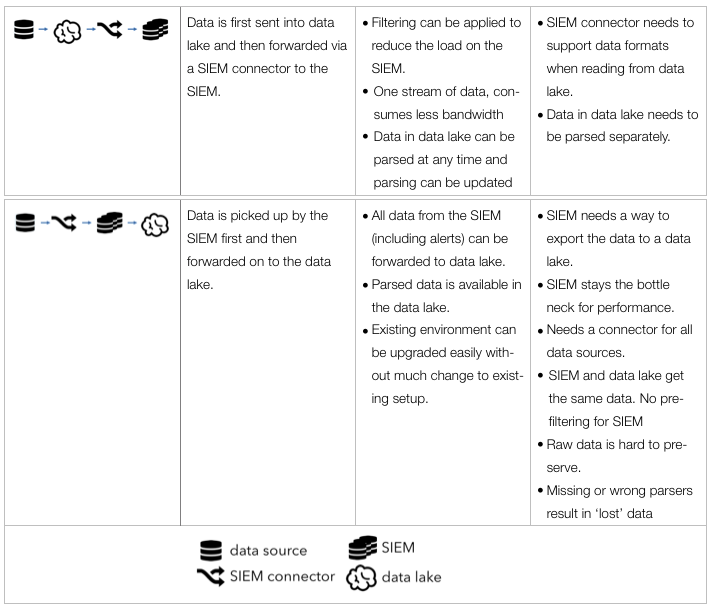
A little teaser from the paper: The following table from the paper summarizes the four main building blocks that can be used to put together a SIEM – data lake integration:
Thanks @antonchuvakin for brainstorming and coming up with the diagram.