In my previous blog post, I ranted a little about database technologies and threw a few thoughts out there on what I think a better data system would be able to do. In this post, I am going to talk a bit about the concept of the Data Lakehouse.
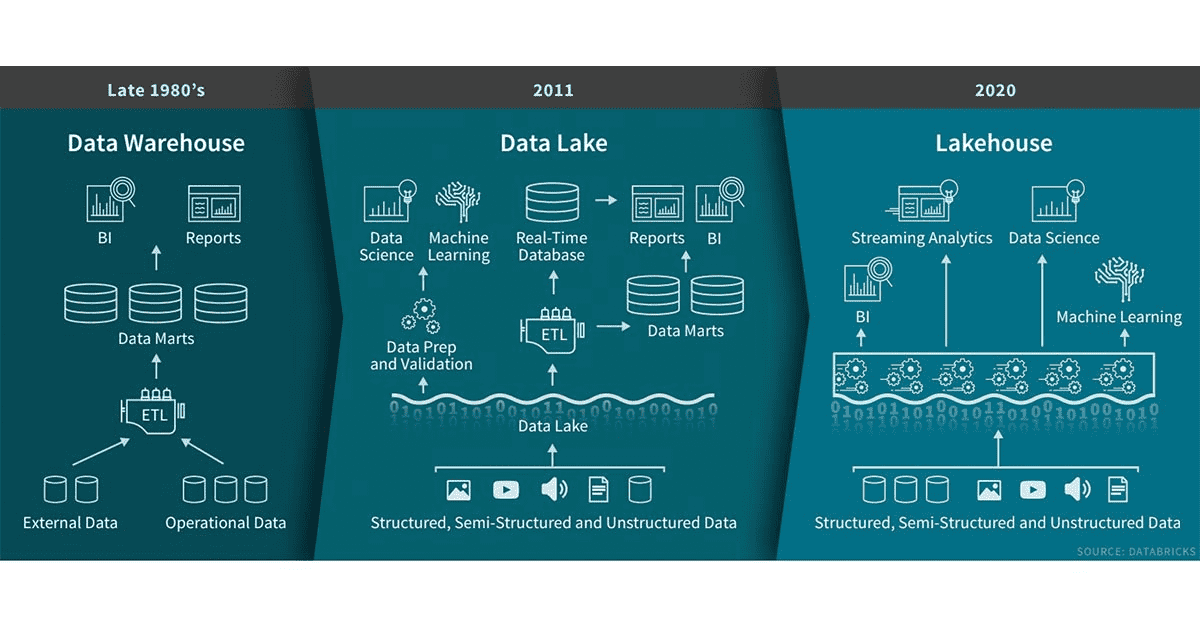
The term ‘data lakehouse‘ has been making the rounds in the data and analytics space for a couple of years. It describes an environment combining data structure and data management features of a data warehouse with the low-cost scalable storage of a data lake. Data lakes have advanced the separation of storage from compute, but do not solve problems of data management (what data is stored, where it is, etc). These challenges often turn a data lake into a data swamp. Said a different way, the data lakehouse maintains the cost and flexibility advantages of storing data in a lake while enabling schemas to be enforced for subsets of the data.
Let’s dive a bit deeper into the Lakehouse concept. We are looking at the Lakehouse as an evolution of the data lake. And here are the features it adds on top:
- Data mutation – Data lakes are often built on top of Hadoop or AWS and both HDFS and S3 are immutable. This means that data cannot be corrected. With this also comes the problem of schema evolution. There are two approaches here: copy on write and merge on read – we’ll probably explore this some more in the next blog post.
- Transactions (ACID) / Concurrent read and write – One of the main features of relational databases that help us with read/write concurrency and therefore data integrity.
- Time-travel – This can feature is sort of provided through the transaction capability. The lakehouse keeps track of versions and therefore allows for going back in time on a data record.
- Data quality / Schema enforcement – Data quality has multiple facets, but mainly is about schema enforcement at ingest. For example, ingested data cannot contain any additional columns that are not present in the target table’s schema and the data types of the columns have to match.
- Storage format independence is important when we want to support different file formats from parquet to kudu to CSV or JSON.
- Support batch and streaming (real-time) – There are many challenges with streaming data. For example the problem of out-of order data, which is solved by the data lakehouse through watermarking. Other challenges are inherent in some of the storage layers, like parquet, which only works in batches. You have to commit your batch before you can read it. That’s where Kudu could come in to help as well, but more about that in the next blog post.
If you are interested in a practitioners view of how increased data loads create challenges and how a large organization solved them, read about Uber’s journey that ended up in the development of Hudi, a data layer that supports most of the above features of a Lakehouse. We’ll talk more about Hudi in our next blog post.
In 2015, I wrote a book about the Security Data Lake. At the time, the big data space was not as mature as today and especially the intersection of big data and security wasn’t a well understood area. Fast forward to today, people are talking about to the “Data Lakehouse“. A new concept that has been made possible by new database technologies, projects, and companies pushing the envelope. All of which are trying to solve our modern data management and analytics challenges. Or said differently, they are all trying to make our data actionable at the lowest possible cost. In this first of three blog post, I am going to look at what happened in the big data world during the past few years. In the second blog post, we’ll explore what a data lakehouse is and we will look around to understand some of the latest big data projects and tools that promise to uncover the secrets hidden in our data.
Let me start with a bit of a rant about database technologies. Back in the day, we had relational databases; the MySQL’s and Oracle’s of the world. And the world was good. Then we realized that not all data and not all access patterns were suited for these databases, so we invented the document stores, the search engines, the graph databases, the key value stores, the columnar databases, etc. And that’s when life got complicated. What database do you use for what purposes? Often it seemed like we’d need multiple ones. But that would have meant we’d needed to duplicate data, pick the right database for the task at hand, synchronize the data, etc. A nightmare. What happened then was that we just started using the technology that seemed to cover most of our needs and abused it for the other tasks. I have seen one too many document stores used to serve complex analytical questions (i.e., asking Lucene to return aggregate metrics and ad-hoc summaries).
Alongside the database technologies themselves, there is a notable secondary trend: increased requirements from a regulatory, privacy, and data locality perspective. Regulations like GDPR are imposing restrictions and requirements on how data can be stored and give individuals the right to see their data and even modify or delete it upon request. Some data stores have come up with privacy features, which are often in harsh contradiction to the insights we are looking for in the data. Finally, with increasingly going global, it matters where we collect and process our data. Not just for privacy purposes, but rather for processing speed and storage requirements. How, for example, do you compute global summaries over your data? Do you bring the data into one data center? Or do you compute local aggregates to then summarize them? Latency and storage costs are important factors to consider.
Wouldn’t it be nice if we had a data system that took care of all the above mentioned requirements automatically? It ingests the data we send to it – structured, unstructured, sensitive, non sensitive, anything. And on the other side, we formulate queries (I think we should keep SQL as the lingua franca for this) to answer the questions we have. Of course, we can add nice visualization layers on top, but that’s icing on the cake. I’d love a self-adjusting system. Don’t make me choose whether I wanted a graph database or not. Don’t make me configure data localities or privacy parameters. Let the system determine the necessary parameters – maybe bring me in the loop for things that the system cannot figure out itself, but make it easy on me. Definitely don’t ask me to create indexes or views. Let the system figure out those properties on the fly, while observing my access patterns. Move the data to where it is needed, create summary tables and materialized views transparently, while keeping storage cost and regulatory constraints in mind.
Now that we talked about storage and access, what about ETL? The challenge with translating data on ingest is that the translation often means loss of information. On the flip side, it makes analytics tasks easier and it helps clean the data. Take security logs (syslog), for example. We could store them in their original form as an unstructured string, or we could parse out every element to store the individual fields in a structured way. The challenge is the parser. If we get things wrong, we will loose entire log records. If, however, we stored the logs in their original form, we could do the transformation (parsing) at the time of analytics. The drawback then being that we will parse the same data multiple times over; every time we query or run any analytics on it. What to do? Again, wouldn’t it be nice if the data system took care of this decision for us? Keep the original data around if necessary, parse where needed, re-parse on error, etc.
Let’s look at one final piece of the data system puzzle, analytics. With the advent of cloud, there has been a big push to centralize analytics. That means all the data has to be shipped to a single, central location. That in itself is not always cheap, nor fast. We need an approach that allows us to keep some data completely decentralized. Leave the data at the place of generation and use the compute there to derive partial answer. Only send around the data that is needed. Again, with all the constraints and requirements we might have, such as compute availability and cost, hybrid data storage, considerations of fail over, redundancy, backups, etc. And again, I don’t want to configure these things. I’d like the system to take care of them after I told it some guiding parameters.
In a future post I will explore what has happened in the last couple of years in the big data ecosystem and what the lakehouse is about. Is there maybe a solution out there that sufficiently satisfies the above requirements?
