Well, not one of my normal blog posts, but I hope some of you geeks out there will find this useful anyways. I will definitely use this post as a reference frequently.
I have been using various flavors of UNIX and their command lines from ksh to bash and zsh for over 25 years and there is always something new to learn to make me faster at the jobs I am doing. One tool that I keep using (despite my growing command of Excel), is VIM coupled with UNIX command line tools. It saves me hours and hours of work all the time.
Well, here are some new things I learned and want to remember from the Well, here are some new things I learned and want to remember from the art of command line github repo:
CTRL-W on the command line deletes the last word
pgrep to search for processes rather than doing the longer version with awk
lsof -iTCP -sTCP:LISTEN -P -n processes listening on TCP ports
Diff two json files: diff <(jq --sort-keys . < file1.json) <(jq --sort-keys . < file2.json) | colordiff | less -R
I totally forgot about csvkit – brew install csvkit
in2csv file1.xls > file1.csv
csvstat data.csv
csvsql --query "select name from data where age > 30" data.csv > old.csv
I just found some additional command son OSX that I wish I had known earlier:
ditto copies one or more source files or directories to a destination directory. If the destination directory does not exist it will be created before the first source is copied. If the destination directory already exists then the source directories are merged with the previous contents of the destination.
pbcopy past data from command line into the clipboard
qlmanage quick view from the command line
This is a great repo as well for great OSX commands.
Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
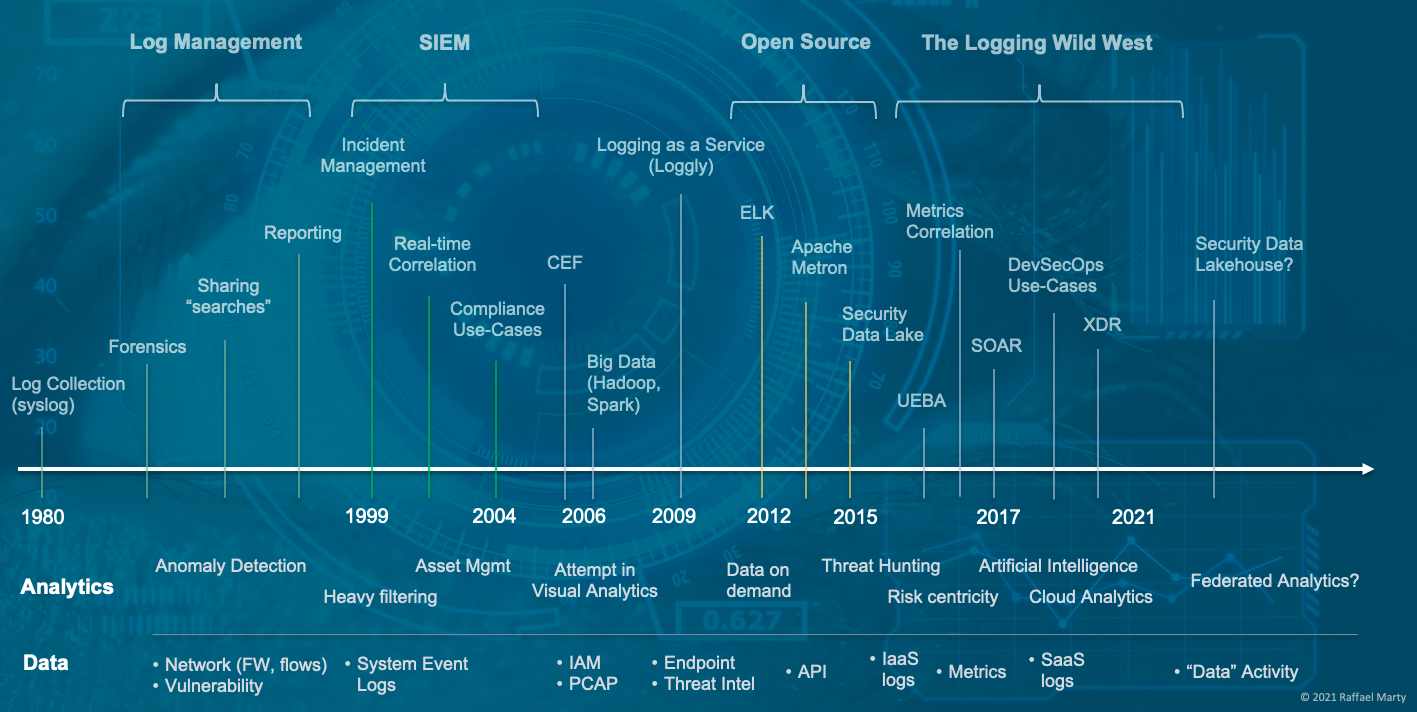
The log management and security information management (SIEM) space have gone through a number of stages to arrive where they are today. I started mapping the space in the 1980’s when syslog entered the world. To make sense of the really busy diagram, the top shows the chronological timeline (not in equidistant notation!), the second swim lane underneath calls out some milestone analytics components that were pivotal at the given times and the last row shows what data sources were added a the given times to the logging systems to gain deeper visibility and understanding. I’ll let you digest this for a minute.
What is interesting is that we started the journey with log management use-cases which morphed into an entire market, initially called the SIM market, but then officially being renamed to security information and event management (SIEM). After that we entered a phase where big data became a hot topic and customers started toying with the idea of building their own logging solutions. Generally not with the best results. But that didn’t prevent some open source movements from entering the map, most of which are ‘dead’ today. But what happened after that is even more interesting. The entire space started splintering into multiple new spaces. First it was products that called themselves user and entity behavior analytics (UEBA), then it was SOAR, and most recently it’s been XDR. All of which are really off-shoots of SIEMs. What is most interesting is that the stand-alone UEBA market is pretty much dead and so is the SOAR market. All the companies either got integrated (acquired) into existing SIEM platforms or added SIEM as an additional use-case to their own platform.
XDR has been the latest development and is probably the strangest of all. I call BS on the space. Some vendors are trying to market it as EDR++ by adding some network data. Others are basically taking SIEM, but are restricting it to less data sources and a more focused set of use-cases. While that is great for end-users looking to solve those use-cases by giving them a better experience, it’s really not much different from what the original SIEMs have been built to do.
If you have a minute and you want to dive into some more of the details of the history, following is a 10 minute video where I narrate the history and highlight some of the pivotal areas, as well as explain a bit more what you see in the timeline.
Thanks to some of my industry friends, Anton, Rui, and Lennart who provided some input on the timeline and helped me plug some of the gaps!
If you liked the short video on the logging history, make sure to check out the full video on the topic of “Driving Value From Security Data”
We have been collecting data to drive security insights for over two decades. We call these tools log management solutions, SIMs (security information management), and XDRs (extended detection and response) platforms. Some companies have also built their own solutions on top of big data technologies. It’s been quite the journey.
At the upcoming ThinkIn conference that LogPoint organized on June 8th, I had the honor of presenting the morning keynote. The topic was “How To Drive Value with Security Data“. I spent some time on reviewing the history of security data, log management, and SIEM. I then looked at where we face most challenges with today’s solutions and what the future holds in this space. Especially with the expansion of the space around UEBA, XDR, SOAR, and TIP, there is no such thing as a standardized platform that one would use to get ahead of security attacks. But what does that mean for you as a consumer or security practitioner, trying to protect your business?
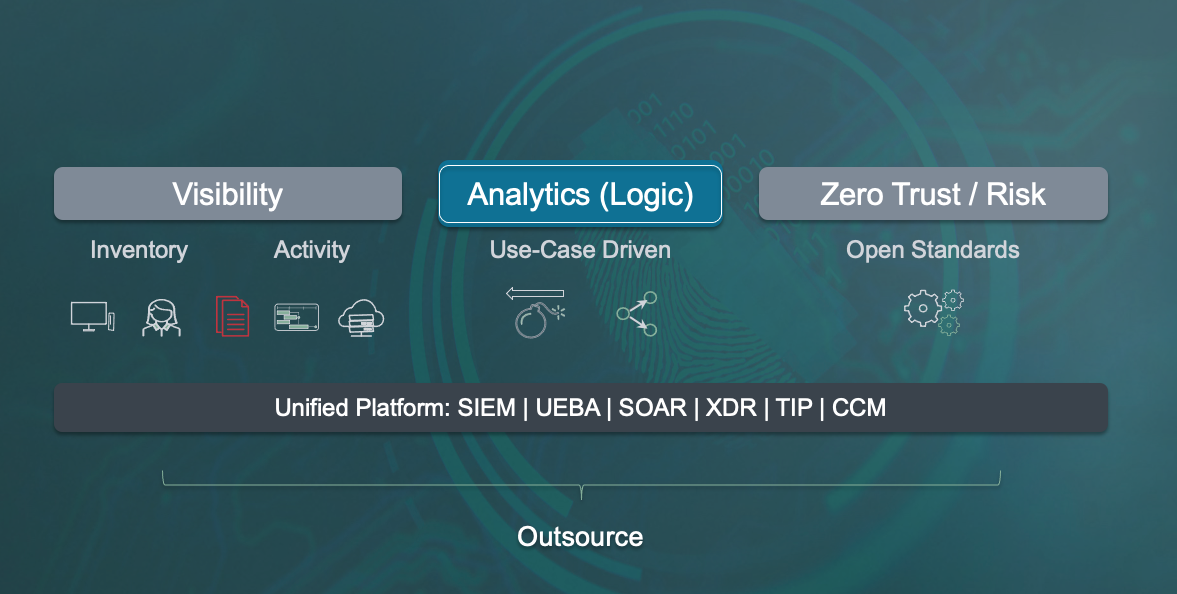
Following is the final slide of the presentation as a bit of a teaser. This is how I summarize the space and how it has to evolve. I won’t take away the thunder and explain the slide just yet. Did you tune into the keynote to get the description?
Before diving into cyber security and how the industry is using AI at this point, let’s define the term AI first. Artificial Intelligence (AI), as the term is used today, is the overarching concept covering machine learning (supervised, including Deep Learning, and unsupervised), as well as other algorithmic approaches that are more than just simple statistics. These other algorithms include the fields of natural language processing (NLP), natural language understanding (NLU), reinforcement learning, and knowledge representation. These are the most relevant approaches in cyber security.
Given this definition, how evolved are cyber security products when it comes to using AI and ML?
I do see more and more cyber security companies leverage ML and AI in some way. The question is to what degree. I have written before about the dangers of algorithms. It’s gotten too easy for any software engineer to play a data scientist. It’s as easy as downloading a library and calling the .start() function. The challenge lies in the fact that the engineer often has no idea what just happened within the algorithm and how to correctly use it. Does the algorithm work with non normally distributed data? What about normalizing the data before inputting it into the algorithm? How should the results be interpreted? I gave a talk at BlackHat where I showed what happens when we don’t know what an algorithm is doing.
Slide from BlackHat 2018 talk about “Why Algorithms Are Dangerous” showing what can go wrong by blindly using AI.
So, the mere fact that a company is using AI or ML in their product is not a good indicator of the product actually doing something smart. On the contrary, most companies I have looked at that claimed to use AI for some core capability are doing it ‘wrong’ in some way, shape or form. To be fair, there are some companies that stick to the right principles, hire actual data scientists, apply algorithms correctly, and interpret the data correctly.
Generally, I see the correct application of AI in the supervised machine learning camp where there is a lot of labeled data available: malware detection (telling benign binaries from malware), malware classification (attributing malware to some malware family), document and Web site classification, document analysis, and natural language understanding for phishing and BEC detection. There is some early but promising work being done on graph (or social network) analytics for communication analysis. But you need a lot of data and contextual information that is not easy to get your hands on. Then, there are a couple of companies that are using belief networks to model expert knowledge, for example, for event triage or insider threat detection. But unfortunately, these companies are a dime a dozen.
That leads us into the next question: What are the top use-cases for AI in security?
I am personally excited about a couple of areas that I think are showing quite some promise to advance the cyber security efforts:
Using NLP and NLU to understand people’s email habits to then identify malicious activity (BEC, phishing, etc). Initially we have tried to run sentiment analysis on messaging data, but we quickly realized we should leave that to analyzing tweets for brand sentiment and avoid making human (or phishing) behavior judgements. It’s a bit too early for that. But there are some successes in topic modeling, token classification of things like account numbers, and even looking at the use of language.
Leveraging graph analytics to map out data movement and data lineage to learn when exfiltration or malicious data modifications are occurring. This topic is not researched well yet and I am not aware of any company or product that does this well just yet. It’s a hard problem on many layers, from data collection to deduplication and interpretation. But that’s also what makes this research interesting.
Given the above it doesn’t look like we have made a lot of progress in AI for security. Why is that? I’d attribute it to a few things:
Access to training data. Any hypothesis we come up with, we have to test and validate. Without data that’s hard to do. We need complex data sets that are showing user interactions across applications, their data, and cloud apps, along with contextual information about the users and their data. This kind of data is hard to get, especially with privacy concerns and regulations like GDPR putting more scrutiny on processes around research work.
A lack of engineers that understand data science and security. We need security experts with a lot of experience to work on these problems. When I say security experts, these are people that have a deep understand (and hands-on experience) of operating systems and applications, networking and cloud infrastructures. It’s unlikely to find these experts who also have data science chops. Pairing them with data scientists helps, but there is a lot that gets lost in their communications.
Research dollars. There are few companies that are doing real security research. Take a larger security firm. They might do malware research, but how many of them have actual data science teams that are researching novel approaches? Microsoft has a few great researchers working on relevant problems. Bank of America has an effort to fund academia to work on pressing problems for them. But that work generally doesn’t see the light of day within your off the shelf security products. Generally, security vendors don’t invest in research that is not directly related to their products. And if they do, they want to see fairly quick turn arounds. That’s where startups can fill the gaps. Their challenge is to make their approaches scalable. Meaning not just scale to a lot of data, but also being relevant in a variety of customer environments with dozens of diverging processes, applications, usage patterns, etc. This then comes full circle with the data problem. You need data from a variety of different environments to establish hypotheses and test your approaches.
Is there anything that the security buyer should be doing differently to incentivize security vendors to do better in AI?
I don’t think the security buyer is to blame for anything. The buyer shouldn’t have to know anything about how security products work. The products should do what they claim they do and do that well. I think that’s one of the mortal sins of the security industry: building products that are too complex. As Ron Rivest said on a panel the other day: “Complexity is the enemy of security”.
Also have a look at the VentureBeat article feating some quotes from me.
On a recent consulting engagement with Cynergy Partners, we needed to decipher the security product market to an investment firm that normally doesn’t invest in cyber security. One of the investor’s concerns was that a lot of cyber companies are short-lived businesses due to the threats changing so drastically quick. One day it’s ransomware X, the next day it’s a new variant that defeats all the existing protective measures and then it’s a new SQL injection variant that requires a completely different security approach to stop it. How in the world would an investor ever get comfortable investing in a short-lived business like that?
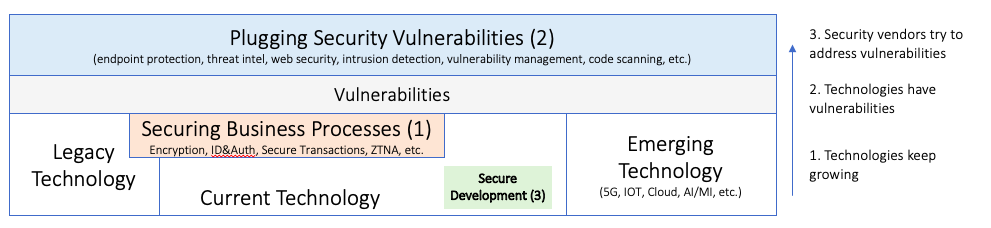
In light of trying to explain the security product market and to explain that there are not just security solutions that are chasing the next attack, we developed a model to highlight the fact that security often needs to be deeply embedded into business processes. As a result, it becomes far more likely for security solutions to have a longer ‘shelf-life’. Here is the diagram that helps explain the concept:
The diagram shows from left to right the technology evolution. You have legacy technology that is still running in organizations and drives businesses, for example your mainframes. Then you have current technologies and finally emerging technologies, such as 5G, IoT, AI, etc. All of the technologies have vulnerabilities that we learn about over time and we need to secure in some way. You can imagine that most every technology will need a different way to secure it, which creates the crazy complex ecosystem of security products and services.
With that setup, we end up in a world with three different types of security products, which
Secure Business Processes
Plug Security Vulnerabilities
Enable Secure Software Development
As you can quickly see, the first and third type of security solutions are ones that do not change with the type of attacks or exploits. They are more technology and business use-case oriented. That also means that security products do not need to change drastically if new vulnerabilities are discovered or new attack methods are being used by adversaries.
Showing this diagram for our investment client helped them get more comfortable that they are looking at an investment that lives on the ‘steady’ or ‘sticky’ side of the security product spectrum where they do not have to worry about getting obsolete tomorrow just because the world of ‘attacks’ has changed into the next type of security exploits.
Asset management is one of the core components of many successful security programs. I am an advisor to Panaseer, a startup in the continuous compliance management space. I recently co-authored a blog post on my favorite security metric that is related to asset management:
How many assets are in the environment?
A simple number. A number that tells a complex story though if collected over time. A metric also that has a vast number of derivatives that are important to understand and one that has its challenges to be collected correctly. Just think about how you’d know how many assets there are at every moment in time? How do you collect that information in real-time?
The metric is also great to start with to then break it down along additional dimensions. For example:
How many assets are managed versus unmanaged (e.g., IOT devices)
Who are the owners of the assets and how many assets can we assign an owner for?
What does the metric look like broken down by operating system, by business unit, by department, by assets that have control violations, etc.
Where is the asset located?
Who is using the asset?
And then, as with any metric, we can look at the metrics not just as a single instance in time, but we can put them into context and learn more about our asset landscape:
How does the number behave over time? Any trends or seasonalities?
Can we learn the uncertainty associated with the metric itself? Or in other terms, what’s the error range?
Can we predict the asset landscape into the future?
Are there certain behavioral patterns around when we see the assets on the network?
I am just scratching the surface of this metric. Read the full blog post to learn more and explore how continuous compliance monitoring can help you get your IT environment under control.
It’s already early March and the year is in full swing. Covid is still raging and we have been seeing some crazy weather patterns, especially in the south of the United States. While snowed in here in Texas, I took some time to reflect on what’s driving cyber security spend and customer focus this year. Overall, we can summarize the 2021 trends under the term of the “Unbound Enterprise“. You will see why when you look at the list of business drivers below. If you run a security business, you might want to see how your company caters to these trends and if you are in a role of protecting a company, ask yourself whether you are prepared for these scenarios:
Work from Home – The way that knowledge workers are doing their work has changed. For good. Most organizations, even after Covid, will allow their workforce to work from home. That brings with it an emphasize on things like endpoint security, secure remote access, and secure home infrastructure. The two big trends here from a market perspective are Secure Access Service Edge (SASE) and Zero Trust Network Access (ZTNA). Where the latter has initiated the long needed shift of focus to risk rather than event driven systems.
Supply Chain – Pretty much every product on the general markets is built from multiple supply sources; raw materials, specialized and integrated components. The production process is generally using tooling and machinery that is provided by another part of the supply chain. Think of third-party computer systems or MCU controlled infrastructure like HVACs, cloud infrastructures, and even external service personnel working on any of the infrastructure or processes of your company. Like most security challenges, securing the supply chain starts with visibility. Do you know which components are part of your supply chain? Who is the supplier and how trustworthy is said supplier?
SaaS Applications – Companies are moving more and more of their supporting infrastructure to third-party SaaS applications: Workday, Salesforce, Dropbox, even ERP systems are moving over to cloud services. Lower TCO, less maintenance headaches, etc. This means that not just backoffice services are moving to SaaS, but security product vendors also have to think about their product offerings and how they can provide SaaS enabled products to their customer base. Do it now. Do it today and not in three years when you have been pushed out of the market because you didn’t have a cloud offering.
Hybrid Infrastructures – Not all infrastructure will immediately move to the cloud. We will have to live through a time of hybrid infrastructures. The trend is for services to move into the cloud, but some things just cannot be moved yet for a myriad of reasons. This means that your security solutions probably have to support hybrid customer infrastructures for a while. Data centers won’t disappear over night. You can also get cyber incident response management so you have the ability to respond to cyber security incidents immediately. Nettitude explains why cyber security incident response is a big deal.
Insider Threat – Insider abuse is a concern. Do you know how many of your engineers are taking source code with them when they leave the company? Generally it’s not a malicious act, but there is a certain degree of ownership that a software developer feels toward the code that they wrote. Of course, legally, that code belongs to the company and it’s illegal for the developer to take the code with them, but go check what’s reality. This translates into any job role. In addition, espionage is on the rise. The good news is that if you protect your critical intellectual property (IP), you can fend off not just insiders, but also external attacks as their goal is primarily to steal, modify, or destroy your data.
Board of Directors Cyber Committees – The regulatory environment has been pushing boards to pay more attention to the company’s security practices and procedures. The board is liable for negligence on the security side. Therefore, many boards have started cyber committees that evaluate and drive the security practices of the organization. Gartner predicts that 40% of boards will have a dedicated cybersecurity committee by 2025. How can we help these committees do their job? How does your security product help with surfacing and reducing risk to the company in a measurable way?
I hope these themes help you guide your security (product) organizations for the next bit to come. I’ll leave all of you who think about security products with a final thought:
Attack vectors (threats) are constantly changing. New vulnerabilities are found and exploited, new technology stacks have to be secured, and humans keep making mistakes when configuring systems, securing their data, and are prone to social engineering. With these constantly moving targets, what are the constants that we can (have to) secure in order to escape the broken cycle of security?
I recently wrote a post about the concept of the Data Lakehouse, which in some ways, brings components of what I outlined in the first post around my desires for a new database system to life. In this post, I am going to make an attempt to describe a roll-up of some recent big data developments that you should be aware of.
Let’s start with the lowest layer in the database or big data stack, which in many cases is Apache Spark as the processing engine powering a lot of the big data components. The component itself is obviously not new, but there is an interesting feature that was added in Spark 3.0, which is the Adaptive Query Execution (AQE). This features allows Spark to optimize and adjust query plans based on runtime statistics collected while the query is running. Make sure to turn it on for SparkSQL (spark.sql.adaptive.enabled) as it’s off by default.
The next component of interest is Apache Kudu. You are probably familiar with parquet. Unfortunately, parquet has some significant drawbacks, like it’s innate batch approach (you have to commit written data before it’s available for read). Specifically when it comes to real-time applications. Kudu’s on-disk data format closely resembles parquet, with a few differences to support efficient random access as well as updates. Also notable is that Kudu can’t use cloud object storage due to it’s use of Ext4 or XFS and the reliance on a consensus algorithm which isn’t supported in cloud object storage (RAFT).
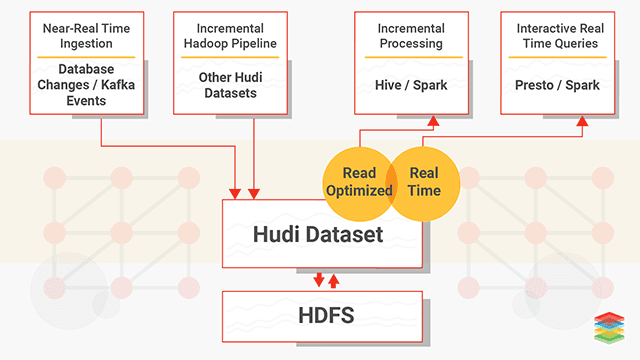
At the same layer in the stack as Kudu and parquet, we have to mention Apache Hudi. Apache Hudi, like Kudu, brings stream processing to big data by providing fresh data. Like Kudu it allows for updates and deletes. Unlike Kudu though, Hudi doesn’t provide a storage layer and therefore you generally want to use parquet as its storage format. That’s probably one of the main differences, Kudu tries to be a storage layer for OLTP whereas Hudi is strictly OLAP. Another powerful feature of Hudi is that it makes a ‘change stream’ available, which allows for incremental pulling. With that it supports three types of queries:
Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action. Here the concepts of ‘copy on write’ and ‘merge on read’ become important. The latter being useful for near real-time querying.
Incremental Queries : Queries only see new data written to the table, since a given commit/compaction.
Read Optimized Queries : Queries see the latest snapshot of table as of a given commit/compaction action. This is mostly used for high speed querying.
The Hudi documentation is a great spot to get more details. And here is a diagram I borrowed from XenoStack:
What then is Apache Iceberg and the Delta Lake then? These two projects yet another way of organizing your data. They can be backed by parquet, and each differ slightly in the exact use-cases and how they handle data changes. And just like Hudi, they both can be used with Spark and Presto or Hive. For a more detailed discussion on the differences, have a look here and this blog walks you through an example of using Hudi and Delta Lake.
Enough about tables and storage formats. While they are important when you have to deal with large amounts of data, I am much more interested in the query layer.
The project to look at here is Apache Calcite which is a ‘data management framework’ or I’d call it a SQL engine. It’s not a full database mainly due to omitting the storage layer. But it supports multiple storage engines. Another cool feature is the support for streaming and graph SQL. Generally you don’t have to bother with the project as it’s built into a number of the existing engines like Hive, Drill, Solr, etc.
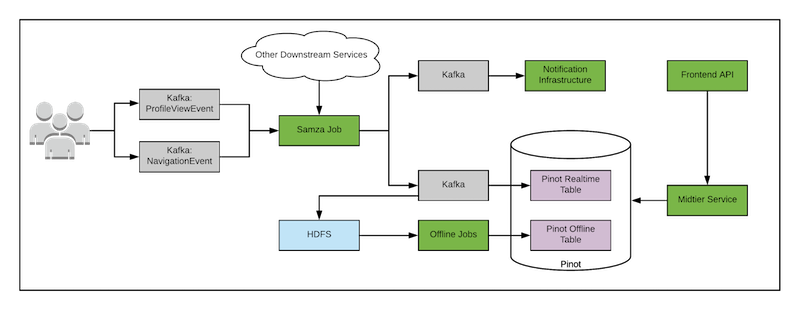
As a quick summary and a slightly different way of looking at why all these projects mentioned so far have come into existence, it might make sense to roll up the data pipeline challenge from a different perspective. Remember the days when we deployed Lambda architectures? You had two separate data paths; one for real-time and one for batch ingest. Apache Flink can help unify these two paths. Others, instead of rewriting their pipelines, let developers write the batch layer and then used Calcite to automatically translate that into the real-time processing code and to merge the real-time and batch outputs, used Apache Pinot.
The nice thing is that there is a Presto to Pinot connector, allowing you to stay in your favorite query engine. Sidenote: don’t worry about Apache Samza too much here. It’s another distributed processing engine like Flink or Spark.
Enough of the geekery. I am sure your head hurts just as much as mine, trying to keep track of all of these crazy projects and how they hang together. Maybe another interesting lens would be to check out what AWS has to offer around databases. To start with, there is PartiQL. In short, it’s a SQL-compatible query language that enables querying data regardless of where or in what format it is stored; structured, unstructured, columnar, row-based, you name it. You can use PartiQL within DynamoDB or the project’s REPL. Glue Elastic views also support PartiQL at this point.
Well, I get it, a general purpose data store that just does the right thing, meaning it’s fast, it has the correct data integrity properties, etc, is a hard problem. Hence the sprawl of all of these data stores (search, graph, columnar, row) and processing and storage projects (from hudi to parquet and impala back to presto and csv files). But eventually, what I really want is a database that just does all these things for me. I don’t want to learn about all these projects and nuances. Just give me a system that lets me dump data into it and answers my SQL queries (real-time and batch) quickly.
In my previous blog post, I ranted a little about database technologies and threw a few thoughts out there on what I think a better data system would be able to do. In this post, I am going to talk a bit about the concept of the Data Lakehouse.
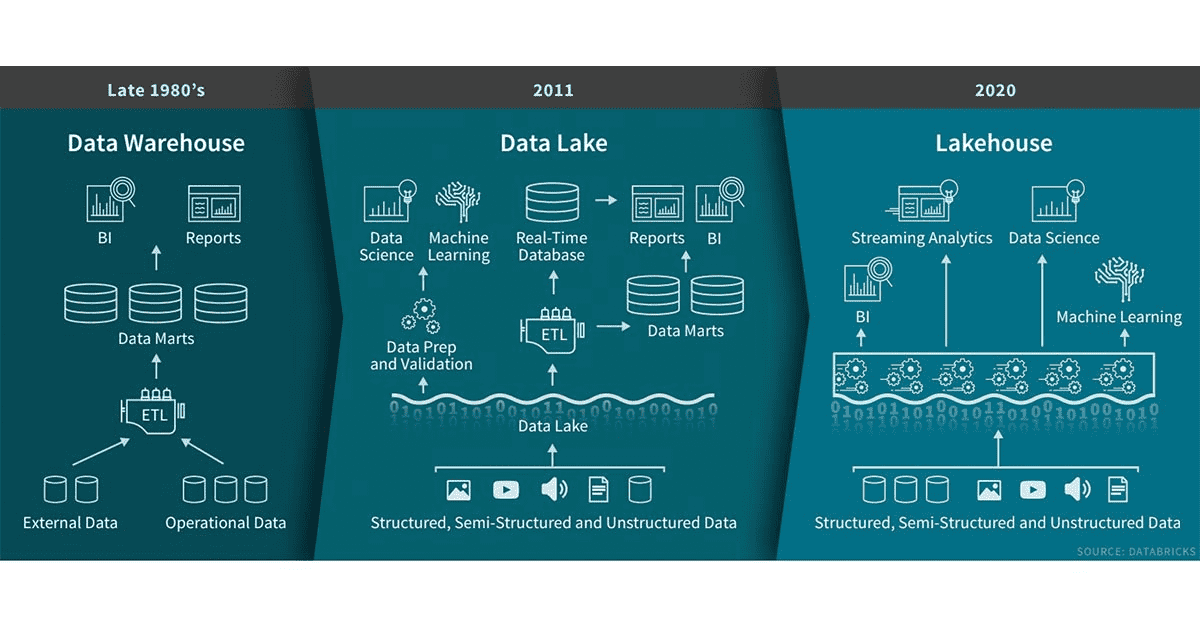
The term ‘data lakehouse‘ has been making the rounds in the data and analytics space for a couple of years. It describes an environment combining data structure and data management features of a data warehouse with the low-cost scalable storage of a data lake. Data lakes have advanced the separation of storage from compute, but do not solve problems of data management (what data is stored, where it is, etc). These challenges often turn a data lake into a data swamp. Said a different way, the data lakehouse maintains the cost and flexibility advantages of storing data in a lake while enabling schemas to be enforced for subsets of the data.
Let’s dive a bit deeper into the Lakehouse concept. We are looking at the Lakehouse as an evolution of the data lake. And here are the features it adds on top:
Data mutation – Data lakes are often built on top of Hadoop or AWS and both HDFS and S3 are immutable. This means that data cannot be corrected. With this also comes the problem of schema evolution. There are two approaches here: copy on write and merge on read – we’ll probably explore this some more in the next blog post.
Transactions (ACID) / Concurrent read and write – One of the main features of relational databases that help us with read/write concurrency and therefore data integrity.
Time-travel – This can feature is sort of provided through the transaction capability. The lakehouse keeps track of versions and therefore allows for going back in time on a data record.
Data quality / Schema enforcement – Data quality has multiple facets, but mainly is about schema enforcement at ingest. For example, ingested data cannot contain any additional columns that are not present in the target table’s schema and the data types of the columns have to match.
Storage format independence is important when we want to support different file formats from parquet to kudu to CSV or JSON.
Support batch and streaming (real-time) – There are many challenges with streaming data. For example the problem of out-of order data, which is solved by the data lakehouse through watermarking. Other challenges are inherent in some of the storage layers, like parquet, which only works in batches. You have to commit your batch before you can read it. That’s where Kudu could come in to help as well, but more about that in the next blog post.
If you are interested in a practitioners view of how increased data loads create challenges and how a large organization solved them, read about Uber’s journey that ended up in the development of Hudi, a data layer that supports most of the above features of a Lakehouse. We’ll talk more about Hudi in our next blog post.