
After my latest blog post on “Machine Learning and AI – What’s the Scoop for Security Monitoring?“, there was a quick discussion on twitter and Shomiron made a good point that in my post I solely focused on supervised machine learning.
In simple terms, as mentioned in the previous blog post, supervised machine learning is about learning with a training data set. In contrast, unsupervised machine learning is about finding or describing hidden structures in data. If you have heard of clustering algorithms, they are one of the main groups of algorithms in unsupervised machine learning (the other being association rule learning).
There are some quite technical problems with applying clustering to cyber security data. I won’t go into details for now. The problems are related to defining distance functions and the fact that most, if not all, clustering algorithms have been built around numerical and not categorical data. Turns out, in cyber security, we mostly deal with categorical data (urls, usernames, IPs, ports, etc.). But outside of these mathematical problems, there are other problems you face with clustering algorithms. Have a look at this visualization of clusters that I created from some network traffic:
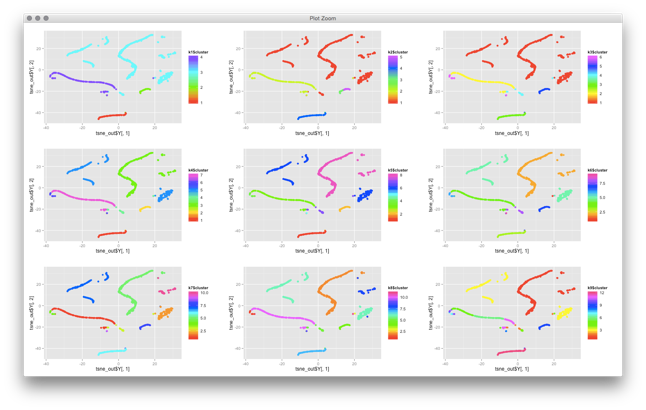
Some of the network traffic clusters incredibly well. But now what? What does this all show us? You can basically do two things with this:
- You can try to identify what each of these clusters represent. But the explainability of clusters is not built into clustering algorithms! You don’t know why something shows up on the top right, do you? You have to somehow figure out what this traffic is. You could run some automatic feature extraction or figure out what the common features are, but that’s generall not very easy. It’s not like email traffic will nicely cluster on the top right and Web traffic on the bottom right.
- You may use this snapshot as a baseline. In fact, in the graph you see individual machines. They cluster based on their similarity of network traffic seen (with given distance functions!). If you re-run the same algorithm at a later point in time, you could try to see which machines still cluster together and which ones do not. Sort of using multiple cluster snapshots as anomaly detectors. But note also that these visualizations are generally not ‘stable’. What was on top right might end up on the bottom left when you run the algorithm again. Not making your analysis any easier.
If you are trying to implement case number one above, you can make it a bit little less generic. You can try to inject some a priori knowledge about what you are looking for. For example, BotMiner / BotHunter uses an approach to separate botnet traffic from regular activity.
These are some of my thoughts on unsupervised machine learning in security. What are your use-cases for unsupervised machine learning in security?
PS: If you are doing work on clustering, have a look at t-SNE. It’s a clustering algorithm that does a multi-dimensional projection of your data into the 2-dimensional space. I have gotten incredible results with it. I’d love to hear from you if you have used the algorithm.
My thinking is this. Apart from some maybe very discrete application looking for something very specific, I believe a solution hierarchy is required. Something like – start with a relational model of who-talks-to-who and then learn the nature of those conversations between certain types of nodes. From here we may be able to identify normal relationships and relationship structures versus things possibly not normal.
Then couple this type of information with other information sources to try to strengthen the findings. i.e. of a relationship between nodes is abnormal, then may other sources of information may also indicate abnormal behaviour. i.e. ensemble learning approach.
Hope that makes some sense.
Comment by Tony Kirkham — October 28, 2017 @ 4:53 pm
Well, if I understand you correctly – your approach seems logical, but in practice won’t work that well. The problem is that activity is not stable. Hardly any is. Relationships change over time. While you are on the right path, there is a lot of detail that makes or breaks your approach.
Have you implemented this? If so, I’d love to hear more about the details. Maybe we can compare notes?
Reminds me of a company that uses social network analysis to analyze the connection graph of a network of computers. They are using all kinds of graph measures to find anomalies. Funny enough, simple statistics can do exactly the same – with much less compute power involved. Oh, the joys of complex algorithms and blinding people with fancy words. Page rank on a network of computer communications anyone? 🙂
Comment by Raffael Marty — November 5, 2017 @ 4:35 pm