Yesterday, we brought Security Chat back to Zurich for its sixth edition and it was everything I had hoped for: brilliant talks, a packed room, and the joy of reconnecting with friends old and new. What started back in 2012 as an informal gathering of security enthusiasts has grown into a tradition where community and ideas come together.
This year we had five lightning talks. Each one very different in style, but all equally thought-provoking:
Candid Wüest – Why AI-Powered Malware Won’t Kill You (Yet)
Candid cut through the hype around “AI-driven malware.” He explained the difference between AI-generated malware (just code produced by LLMs) and AI-powered malware (where AI runs inside the malicious code). While there are proof-of-concepts in the wild, protection stacks still hold up. Behavior-based detection and layered defenses remain effective. His takeaway: AI will eventually give attackers new tools, but defenders are not out of the game.
Joshua Rawles – The Global Impact of a Modern Phishing-as-a-Service Operation
Josh gave us an inside look at the booming phishing-as-a-service industry. For as little as $50 a month, criminals can buy turnkey kits that bypass MFA, come with 24/7 “support,” and scale to tens of thousands of victims. His case study on Storm-1167 (“FluorStorm”) showed just how industrialized this has become, with thousands of domains, Telegram bots for real-time stolen credentials, and devastating impact on nonprofits. His message: MFA is necessary but not sufficient; phishing-resistant authentication and faster takedowns are critical.
Barbara Dravec – Drawn to Encrypt: A Visual Trail from OTP to RSA
Barbara brought cryptography to life with a visual storytelling approach. Mapping concepts like one-time pads, pseudo-random generators, and RSA to vivid imagery from the natural world (snakes, owls, octopuses, and more). It was a refreshing, creative reminder that explaining security to non-experts requires more than equations. It sometimes requires narratives that people can connect to.
Advije Rizvani – AI on Wall Street: Smart, Fast… and Surprisingly Fragile
Advije, a PhD student in Liechtenstein, showed how machine learning systems that drive algorithmic trading can be tricked with subtle, temporary data manipulations. A single manipulated data point can cause wrong trades, eroding portfolio performance over time. Her research raises a sobering question: in high-stakes financial markets, how do we know whether losses are due to bad luck, bad models… or deliberate attacks?
Elliott – When Cookies Collide: The Overlooked Attack Vector
Elliott closed the night with a deep dive into cookie tossing, a little-known but powerful web attack. By controlling a subdomain, an attacker can “toss” malicious cookies that hijack authentication flows or manipulate transactions on the parent domain. He walked us through real-world cases and defenses and highlighting how a small misconfiguration can open the door to session hijacking and data theft.
More Than Talks—It’s About Community
What I loved most about Security Chat 6.0 wasn’t just the talks, but the variety of voices and the energy in the room. We had people flying in from London, driving hours through traffic, and carving out time to share ideas. We had job seekers and companies hiring. We had old friends, new connections, and plenty of wine and bagel bites to keep conversations flowing.
A big thank you to our sponsor 1Password for supporting the evening, to the speakers for sharing their insights, and to everyone who showed up to make this community vibrant.
As I said on stage: cybersecurity has given me so much over the years. Events like this are my way of giving back by fostering connection, sparking ideas, and reminding us all that innovation doesn’t happen in isolation.
See you at the next Security Chat – whenever and wherever it may be.
Thanks to everyone who joined the panel at the BlackHat Innovators & Investors Summit — it was a fast, practical session and full of real, repeatable advice. Below I’ve distilled the conversation into the speakers and the most actionable takeaways founders, investors and channel leaders can use.
Who Spoke
Daniel “DB” Bernard — Chief Business Officer, CrowdStrike
Matt Berry — Global Field CTO, Cyber, World Wide Technology (WWT)
Chris Bisnett — Co-founder & CTO, Huntress
Peter Bryant — Market Analyst, Canalys
Moderator: Raffael Marty, Operating Advisor
Top-line Thesis
Great product is necessary but not sufficient. If you want scale and durability you must design product, GTM, pricing and operations for the channel — MSPs, VARs, MSSPs, distributors and hyperscaler marketplaces. Get those pieces aligned and the channel becomes your growth engine and a moat.
The Most Important, Actionable Insights
1) Start with real customer evidence — then bring partners in
Close a first few deals directly and then ask: Who do you buy through? If the customer uses a reseller or integrator, bring that partner into the next conversation.
A partner introduced by a customer is infinitely more effective than cold outreach.
2) Target, pilot, then scale (regional first)
Don’t boil the ocean. Pick a geography or vertical where a partner has influence, run an enablement-intensive pilot, close a few joint deals, and let the wins spread organically through the partner organization.
Grassroots wins (regional proof points) are how startup products get noticed inside large SIs and disti sales orgs.
3) Engineer the product for MSPs and scale
Some technical must-haves for MSPs: multi-tenancy, frictionless provisioning, usage-based billing, robust reporting, and minimal support overhead (no reboots, simple deployment).
Build integrations with RMM/PSA tools. Partners won’t adopt tools that don’t fit their stack.
4) Use hyperscaler marketplaces as a growth hack
AWS/Azure/Google marketplaces are a procurement shortcut — customers can spend cloud credits and close without long vendor approvals. CrowdStrike and others proved this: marketplace adoption accelerated scale dramatically.
Prioritize marketplace readiness early (billing, security/compliance, packaging).
5) Think of channel margin as external sales / commission
Yes, margins look worse on paper — but compare to the true CAC of building a direct sales force. That margin buys you reach and reduces acquisition risk (you only pay when a partner sells).
Measure partner-sourced vs partner-influenced revenue and the CAC of each.
6) Don’t assume distis/VARs will sell without support
Listing in a distributor catalog is not the finish line. You must: enable, co-market, provide lead flow, run joint sales plays, and sometimes front-end incentives to get sellers focused on your SKU.
Short-term investment in enablement and marketing is how you get long-term pull-through.
7) Build partner economics and enablement as products
Provide free (or low-cost) certification, sales playbooks, demo environments, one-click onboarding, and co-branded assets. These reduce time-to-first-deal and lower partner friction.
Consider usage-based billing to match MSP economics: partners want to align cost with consumed endpoints/services.
8) Decide and double-down on one partner type first
MSP vs MSSP vs VAR vs SI: each requires a different product shape and GTM. Nail one, then expand. Trying to serve all at once dilutes focus and kills momentum.
9) Invest in partner success and low-touch CSM automation
With thousands of SMB endpoints, you can’t scale human CSM for every account. Automate onboarding, monitoring, renewal nudges and migration tools — make it easy for MSPs to manage many customers.
10) Metrics you should be tracking from day 1
Time-to-first-deal with partner (by partner type)
Partner-sourced pipeline and partner-influenced revenue
Onboarding time per MSP customer (time-to-live)
Churn by partner / churn during partner transitions
Net retention for partner-sourced customers
Practical checklist for founders (do this tomorrow)
Pull your top 3 customers and ask: who did you buy through?
Pick one partner (regional or niche) and design a 90-day pilot with joint enablement and a measurable close objective.
Audit product integration: do you have PSA/RMM connectors? If not, roadmap one.
Prepare an AWS/Azure/Google marketplace package (billing, security, description, packaging).
Create a partner enablement kit: demo script, short playbook, 1-page technical install guide, and a free certification.
Model partner economics as commission vs. CAC — present it to your board/investors as external sales.
Instrument partner metrics in your analytics and report them weekly.
Suggested questions to ask a distributor / VAR / SI when exploring partnership
Who in your organization will sell and who will implement our solution? (names/roles)
What does success look like in the first 90 days? How many joint opportunities will you target?
Which 3 vendors do you co-sell with today (and how do we integrate with them)?
What enablement will you need from us (sales motion, demo environment, pricing, rebates)?
How will leads/credit/margin be handled if a customer comes direct?
For investors: what to look for in a channel-first startup
Product designed for the channel: multi-tenancy, RMM/PSA integrations, usage billing.
Early partner proofs: paying partners or partner-introduced deals, not just distributor listings.
A go-to-market playbook for partner enablement (documented processes, enablement kits, measurable time-to-first-deal).
Marketplace strategy and early traction (even if small, momentum matters).
Closing takeaways (what I heard loud and clear)
The channel is not a shortcut — it’s a discipline. If you commit, build for it, and invest in the partner motion, channel-first companies scale faster and with lower long-term CAC.
Start with customers, pilot locally with partners, engineer for MSP realities, and use marketplaces to accelerate procurement.
Win through repeatable partner plays and measurable enablement — wins scale inside partner organizations.
Thanks again to BlackHat for having us and to the panelists to take time out of their busy schedules to impart these very actionable insights.
Who knows, I might just pick up my blogging again at some point. For now, I posted a short leadership related post on my Leadership | Technology | Spirit blog. Check it out.
Well, not one of my normal blog posts, but I hope some of you geeks out there will find this useful anyways. I will definitely use this post as a reference frequently.
I have been using various flavors of UNIX and their command lines from ksh to bash and zsh for over 25 years and there is always something new to learn to make me faster at the jobs I am doing. One tool that I keep using (despite my growing command of Excel), is VIM coupled with UNIX command line tools. It saves me hours and hours of work all the time.
Well, here are some new things I learned and want to remember from the Well, here are some new things I learned and want to remember from the art of command line github repo:
CTRL-W on the command line deletes the last word
pgrep to search for processes rather than doing the longer version with awk
lsof -iTCP -sTCP:LISTEN -P -n processes listening on TCP ports
Diff two json files: diff <(jq --sort-keys . < file1.json) <(jq --sort-keys . < file2.json) | colordiff | less -R
I totally forgot about csvkit – brew install csvkit
in2csv file1.xls > file1.csv
csvstat data.csv
csvsql --query "select name from data where age > 30" data.csv > old.csv
I just found some additional command son OSX that I wish I had known earlier:
ditto copies one or more source files or directories to a destination directory. If the destination directory does not exist it will be created before the first source is copied. If the destination directory already exists then the source directories are merged with the previous contents of the destination.
pbcopy past data from command line into the clipboard
qlmanage quick view from the command line
This is a great repo as well for great OSX commands.
Last week I keynoted LogPoint’s customer conference with a talk about how to extract value from security data. Pretty much every company out there has tried to somehow leverage their log data to manage their infrastructure and protect their assets and information. The solution vendors have initially named the space log management and then security information and event management (SIEM). We have then seen new solutions pop up in adjacent spaces with adjacent use-cases; user and entity behavior analytics (UEBA) and security orchestration, automation, and response (SOAR) platforms became add-ons for SIEMs. As of late, extended detection and response (XDR) has been used by some vendors to try and regain some of the lost users that have been getting increasingly frustrated with their SIEM solutions and the cost associated for not the return that was hoped for.
In my keynote I expanded on the logging history (see separate post). I am touching on other areas like big data and open source solutions as well and go back two decades to the origins of log management. In the second section of the talk, I shift to the present to discuss some of the challenges that we face today with managing all of our security data and expand on some of the trends in the security analytics space. In the third section, we focus on the future. What does tomorrow hold in the SIEM / XDR / security data space? What are some of the key features we will see and how does this matter to the user of these approaches.
Enjoy the video and check out the slides below as well:
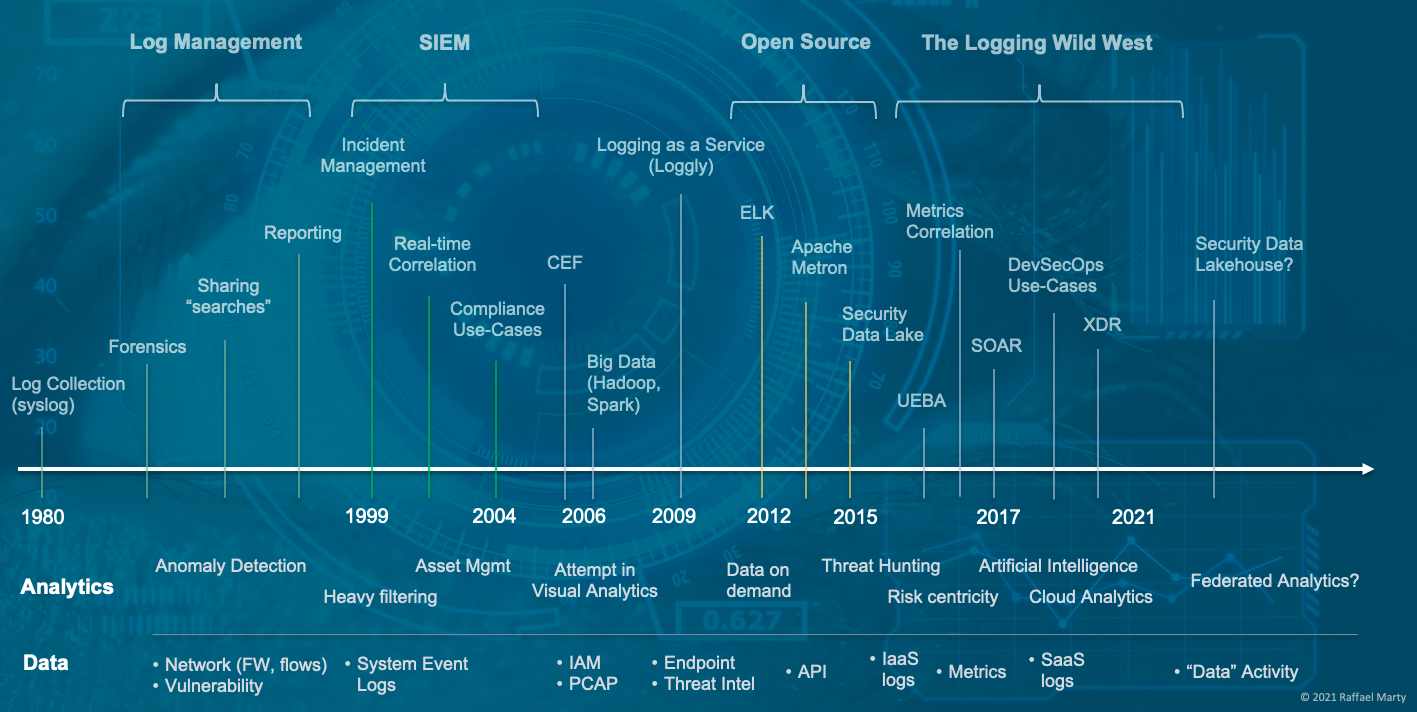
The log management and security information management (SIEM) space have gone through a number of stages to arrive where they are today. I started mapping the space in the 1980’s when syslog entered the world. To make sense of the really busy diagram, the top shows the chronological timeline (not in equidistant notation!), the second swim lane underneath calls out some milestone analytics components that were pivotal at the given times and the last row shows what data sources were added a the given times to the logging systems to gain deeper visibility and understanding. I’ll let you digest this for a minute.
What is interesting is that we started the journey with log management use-cases which morphed into an entire market, initially called the SIM market, but then officially being renamed to security information and event management (SIEM). After that we entered a phase where big data became a hot topic and customers started toying with the idea of building their own logging solutions. Generally not with the best results. But that didn’t prevent some open source movements from entering the map, most of which are ‘dead’ today. But what happened after that is even more interesting. The entire space started splintering into multiple new spaces. First it was products that called themselves user and entity behavior analytics (UEBA), then it was SOAR, and most recently it’s been XDR. All of which are really off-shoots of SIEMs. What is most interesting is that the stand-alone UEBA market is pretty much dead and so is the SOAR market. All the companies either got integrated (acquired) into existing SIEM platforms or added SIEM as an additional use-case to their own platform.
XDR has been the latest development and is probably the strangest of all. I call BS on the space. Some vendors are trying to market it as EDR++ by adding some network data. Others are basically taking SIEM, but are restricting it to less data sources and a more focused set of use-cases. While that is great for end-users looking to solve those use-cases by giving them a better experience, it’s really not much different from what the original SIEMs have been built to do.
If you have a minute and you want to dive into some more of the details of the history, following is a 10 minute video where I narrate the history and highlight some of the pivotal areas, as well as explain a bit more what you see in the timeline.
Thanks to some of my industry friends, Anton, Rui, and Lennart who provided some input on the timeline and helped me plug some of the gaps!
If you liked the short video on the logging history, make sure to check out the full video on the topic of “Driving Value From Security Data”
We have been collecting data to drive security insights for over two decades. We call these tools log management solutions, SIMs (security information management), and XDRs (extended detection and response) platforms. Some companies have also built their own solutions on top of big data technologies. It’s been quite the journey.
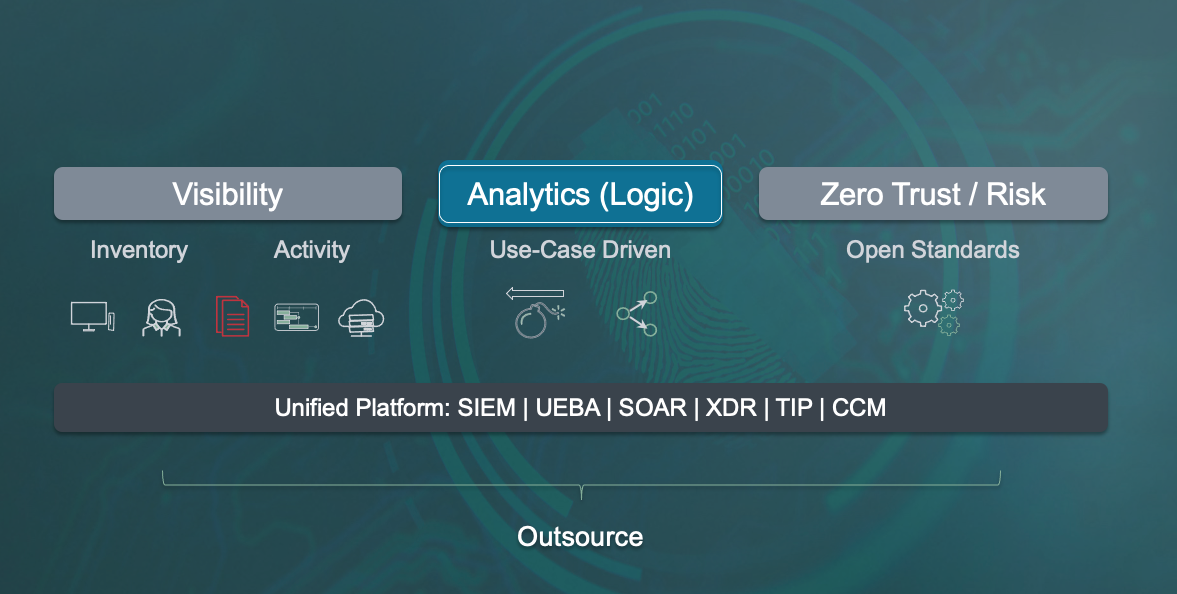
At the upcoming ThinkIn conference that LogPoint organized on June 8th, I had the honor of presenting the morning keynote. The topic was “How To Drive Value with Security Data“. I spent some time on reviewing the history of security data, log management, and SIEM. I then looked at where we face most challenges with today’s solutions and what the future holds in this space. Especially with the expansion of the space around UEBA, XDR, SOAR, and TIP, there is no such thing as a standardized platform that one would use to get ahead of security attacks. But what does that mean for you as a consumer or security practitioner, trying to protect your business?
Following is the final slide of the presentation as a bit of a teaser. This is how I summarize the space and how it has to evolve. I won’t take away the thunder and explain the slide just yet. Did you tune into the keynote to get the description?
Before diving into cyber security and how the industry is using AI at this point, let’s define the term AI first. Artificial Intelligence (AI), as the term is used today, is the overarching concept covering machine learning (supervised, including Deep Learning, and unsupervised), as well as other algorithmic approaches that are more than just simple statistics. These other algorithms include the fields of natural language processing (NLP), natural language understanding (NLU), reinforcement learning, and knowledge representation. These are the most relevant approaches in cyber security.
Given this definition, how evolved are cyber security products when it comes to using AI and ML?
I do see more and more cyber security companies leverage ML and AI in some way. The question is to what degree. I have written before about the dangers of algorithms. It’s gotten too easy for any software engineer to play a data scientist. It’s as easy as downloading a library and calling the .start() function. The challenge lies in the fact that the engineer often has no idea what just happened within the algorithm and how to correctly use it. Does the algorithm work with non normally distributed data? What about normalizing the data before inputting it into the algorithm? How should the results be interpreted? I gave a talk at BlackHat where I showed what happens when we don’t know what an algorithm is doing.
Slide from BlackHat 2018 talk about “Why Algorithms Are Dangerous” showing what can go wrong by blindly using AI.
So, the mere fact that a company is using AI or ML in their product is not a good indicator of the product actually doing something smart. On the contrary, most companies I have looked at that claimed to use AI for some core capability are doing it ‘wrong’ in some way, shape or form. To be fair, there are some companies that stick to the right principles, hire actual data scientists, apply algorithms correctly, and interpret the data correctly.
Generally, I see the correct application of AI in the supervised machine learning camp where there is a lot of labeled data available: malware detection (telling benign binaries from malware), malware classification (attributing malware to some malware family), document and Web site classification, document analysis, and natural language understanding for phishing and BEC detection. There is some early but promising work being done on graph (or social network) analytics for communication analysis. But you need a lot of data and contextual information that is not easy to get your hands on. Then, there are a couple of companies that are using belief networks to model expert knowledge, for example, for event triage or insider threat detection. But unfortunately, these companies are a dime a dozen.
That leads us into the next question: What are the top use-cases for AI in security?
I am personally excited about a couple of areas that I think are showing quite some promise to advance the cyber security efforts:
Using NLP and NLU to understand people’s email habits to then identify malicious activity (BEC, phishing, etc). Initially we have tried to run sentiment analysis on messaging data, but we quickly realized we should leave that to analyzing tweets for brand sentiment and avoid making human (or phishing) behavior judgements. It’s a bit too early for that. But there are some successes in topic modeling, token classification of things like account numbers, and even looking at the use of language.
Leveraging graph analytics to map out data movement and data lineage to learn when exfiltration or malicious data modifications are occurring. This topic is not researched well yet and I am not aware of any company or product that does this well just yet. It’s a hard problem on many layers, from data collection to deduplication and interpretation. But that’s also what makes this research interesting.
Given the above it doesn’t look like we have made a lot of progress in AI for security. Why is that? I’d attribute it to a few things:
Access to training data. Any hypothesis we come up with, we have to test and validate. Without data that’s hard to do. We need complex data sets that are showing user interactions across applications, their data, and cloud apps, along with contextual information about the users and their data. This kind of data is hard to get, especially with privacy concerns and regulations like GDPR putting more scrutiny on processes around research work.
A lack of engineers that understand data science and security. We need security experts with a lot of experience to work on these problems. When I say security experts, these are people that have a deep understand (and hands-on experience) of operating systems and applications, networking and cloud infrastructures. It’s unlikely to find these experts who also have data science chops. Pairing them with data scientists helps, but there is a lot that gets lost in their communications.
Research dollars. There are few companies that are doing real security research. Take a larger security firm. They might do malware research, but how many of them have actual data science teams that are researching novel approaches? Microsoft has a few great researchers working on relevant problems. Bank of America has an effort to fund academia to work on pressing problems for them. But that work generally doesn’t see the light of day within your off the shelf security products. Generally, security vendors don’t invest in research that is not directly related to their products. And if they do, they want to see fairly quick turn arounds. That’s where startups can fill the gaps. Their challenge is to make their approaches scalable. Meaning not just scale to a lot of data, but also being relevant in a variety of customer environments with dozens of diverging processes, applications, usage patterns, etc. This then comes full circle with the data problem. You need data from a variety of different environments to establish hypotheses and test your approaches.
Is there anything that the security buyer should be doing differently to incentivize security vendors to do better in AI?
I don’t think the security buyer is to blame for anything. The buyer shouldn’t have to know anything about how security products work. The products should do what they claim they do and do that well. I think that’s one of the mortal sins of the security industry: building products that are too complex. As Ron Rivest said on a panel the other day: “Complexity is the enemy of security”.
Also have a look at the VentureBeat article feating some quotes from me.
On a recent consulting engagement with Cynergy Partners, we needed to decipher the security product market to an investment firm that normally doesn’t invest in cyber security. One of the investor’s concerns was that a lot of cyber companies are short-lived businesses due to the threats changing so drastically quick. One day it’s ransomware X, the next day it’s a new variant that defeats all the existing protective measures and then it’s a new SQL injection variant that requires a completely different security approach to stop it. How in the world would an investor ever get comfortable investing in a short-lived business like that?
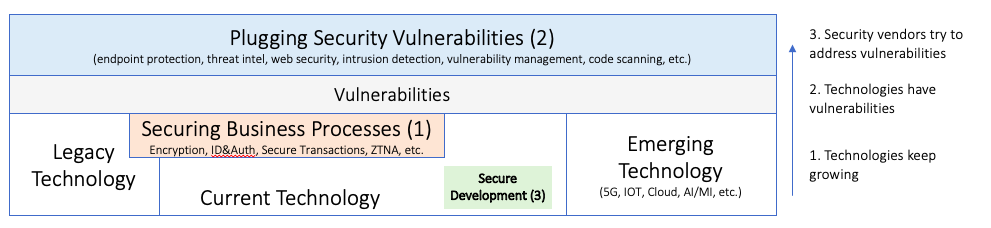
In light of trying to explain the security product market and to explain that there are not just security solutions that are chasing the next attack, we developed a model to highlight the fact that security often needs to be deeply embedded into business processes. As a result, it becomes far more likely for security solutions to have a longer ‘shelf-life’. Here is the diagram that helps explain the concept:
The diagram shows from left to right the technology evolution. You have legacy technology that is still running in organizations and drives businesses, for example your mainframes. Then you have current technologies and finally emerging technologies, such as 5G, IoT, AI, etc. All of the technologies have vulnerabilities that we learn about over time and we need to secure in some way. You can imagine that most every technology will need a different way to secure it, which creates the crazy complex ecosystem of security products and services.
With that setup, we end up in a world with three different types of security products, which
Secure Business Processes
Plug Security Vulnerabilities
Enable Secure Software Development
As you can quickly see, the first and third type of security solutions are ones that do not change with the type of attacks or exploits. They are more technology and business use-case oriented. That also means that security products do not need to change drastically if new vulnerabilities are discovered or new attack methods are being used by adversaries.
Showing this diagram for our investment client helped them get more comfortable that they are looking at an investment that lives on the ‘steady’ or ‘sticky’ side of the security product spectrum where they do not have to worry about getting obsolete tomorrow just because the world of ‘attacks’ has changed into the next type of security exploits.
Asset management is one of the core components of many successful security programs. I am an advisor to Panaseer, a startup in the continuous compliance management space. I recently co-authored a blog post on my favorite security metric that is related to asset management:
How many assets are in the environment?
A simple number. A number that tells a complex story though if collected over time. A metric also that has a vast number of derivatives that are important to understand and one that has its challenges to be collected correctly. Just think about how you’d know how many assets there are at every moment in time? How do you collect that information in real-time?
The metric is also great to start with to then break it down along additional dimensions. For example:
How many assets are managed versus unmanaged (e.g., IOT devices)
Who are the owners of the assets and how many assets can we assign an owner for?
What does the metric look like broken down by operating system, by business unit, by department, by assets that have control violations, etc.
Where is the asset located?
Who is using the asset?
And then, as with any metric, we can look at the metrics not just as a single instance in time, but we can put them into context and learn more about our asset landscape:
How does the number behave over time? Any trends or seasonalities?
Can we learn the uncertainty associated with the metric itself? Or in other terms, what’s the error range?
Can we predict the asset landscape into the future?
Are there certain behavioral patterns around when we see the assets on the network?
I am just scratching the surface of this metric. Read the full blog post to learn more and explore how continuous compliance monitoring can help you get your IT environment under control.