
links for 2009-01-02
Comments on the Syslog Protocol Internet Draft
 I am really late to the game. But finally I read draft-ietf-syslog-protocol-23. This is the new draft for revising the syslog protocol.
I am really late to the game. But finally I read draft-ietf-syslog-protocol-23. This is the new draft for revising the syslog protocol.
Here are some of my comments that I also submitted officially:
- Let me say this first: I really like some of the changes that have been incorporated.
- Syslog message facility: Why still keeping this? The only reason that I see people using the facility is to filter messages. There are better ways to do that. Some of the pre-assigned groups are fairly arbitrary and not even really implemented in most OSs. UUCP subsystem? Who is still using that? I guess the reason for keeping it is backwards compatibility? If possible, I would really like this to be gone.
- Priority calculation: The whole priority field is funky. The priority does not really have any meaning. The order does not imply importance. Why having this at all?
- Timestamps: What’s the reason for having the “T” in the timestamp? Having looked at hundreds of different log formats, I have never seen anything like that. Why doing this?
- Hostname: I am not comfortable with the whole hostname spec. I like that there is an ordering and people are supposed to use FQDNs, but there are many questions about this. To start with, in a lot of UNIX configurations, /etc/hosts contains an entry like
127.0.0.1  localhost.localdomain localhost
The second column is the FQDN (technically). Is that one that can be used? Can you make it clear that this is not what should be used? Same for 127.0.0.1 or the loopback address in general. How does a machine know whether an IP address is static or dynamic? How does a logging application know? I don’t think you will ever know that. Did you mean a private versus a public address? That might be interesting. Furthermore, it should specify which interface’s IP address to use. The interface that the message is sent out on? - Under the section of PROCID: The text is imprecise. This number is not the process ID of the syslog process, it’s the ID of the writing process. The third paragraph talks about detecting restarted applications and somehow mixes in the syslog process. (“might be assigned the same process ID as the previous syslog process“.) This is not clear at all and very very confusing.
- MSGID: Make clear that this ID is local to the application. It’s not a global ID at all.
The biggest issue I have around the SD-ID field:
- I like that the user can extend the set of registered IDs.
- Why is this structure so complicated? Why not going with a simple set of key-value pairs? This whole structure thing is so complicated. Parsing it, you need to keep state! You need to remember the SD-ID for each SD-PARAM. Why introducing this? Just stick with simple key-value pairs. That makes parsing easier. Much easier. And it makes the events easier to produce as well.
- By keeping an explicit message field (the unstructured part), you encourage people to still log in that way. I recommend using an explicit field (or parameter) that can be used to include human readable text. Instead of this:
<165>1 2003-08-24T05:14:15.000003-07:00 192.0.2.1 myproc 8710 - - %% It's time to make the do-nuts.
use:
<165>1 2003-08-24T05:14:15.000003-07:00 192.0.2.1 myproc 8710 - message="%% It's time to make the do-nuts."
or really:
1 2003-08-24 05:14:15.000003-07:00 host=192.0.2.1 process=myproc procid=8710 message="%% It's time to make the do-nuts." - I definitely like the consideration of some of the special fields (structured data IDs). However, they should be used as simple keys (or parameters) that have special meaning.
- Parameter – origin: What does it mean to have multiple origins IPs? Is that a syslog forwarding chain? The document does not say anything about that. Also, we already have the host field in the beginning of the syslog messages. What’s the relationship to that? Or is origin something completely different?
- Parameters – I would really like to see some use-cases for all of the IDs. Especially the sequenceId. I am assuming this is something that the syslog daemon assigns, not the logging application. Right? I think that needs to be clearer. For the sequenceId, what happens for forwarded messages? Are these IDs local? Are they forwarded along with a message? Also, how does the logging application know about the timeQuality? Or if that something that the syslog daemon assigns, how does it know?
- I would really like to see the parameters to go away and have a generic key-value extension. In addition, IANA should have a set of allowed/defined keys. The parameters should be part of those. Each key has a special meaning (semantics). There should be a whole lot of them: src_ip, user_name, etc. Each producer should be free to add additional keys, realizing that not all consumers would understand their semantics. However, the consumers could still read them.
That’s it for now… Let’s see what some of the reactions are going to be.
[tags]IANA, syslog, syslog protocol, IETF, logging[/tags]
Displaying Time in Link Graphs
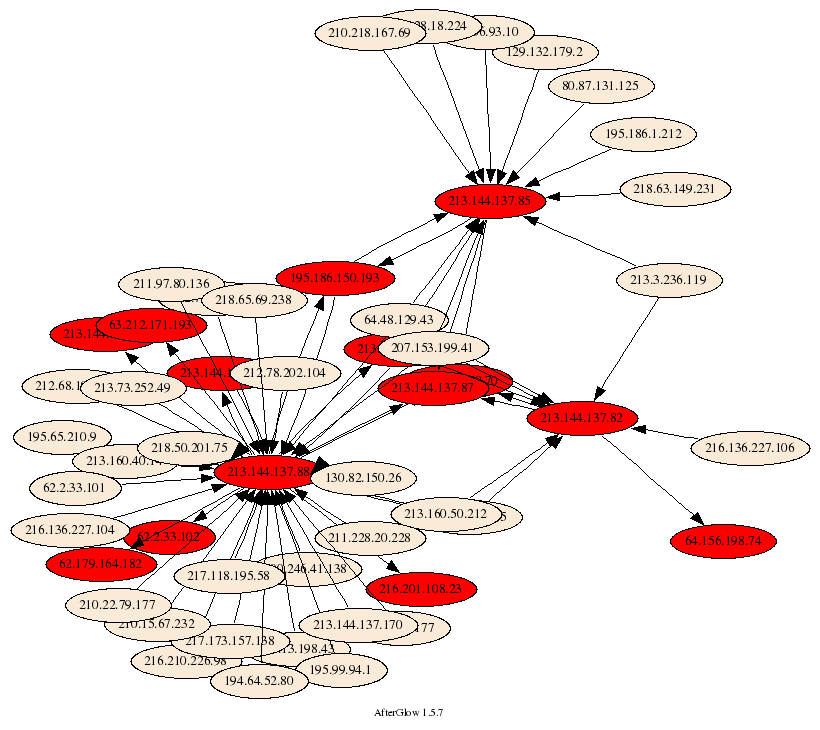 I have been using link graphs a lot in my work of visualizing security data. They are a great methods to display relationships between entities. I guess the most used link graph is one that shows communications of machines. The nodes represent the communicating machines and arrows connecting them show flows.
I have been using link graphs a lot in my work of visualizing security data. They are a great methods to display relationships between entities. I guess the most used link graph is one that shows communications of machines. The nodes represent the communicating machines and arrows connecting them show flows.
You can use color and shape to encode more information, such as the amount o traffic transmitted or a machine’s role. I even extended the graphs to show three types of nodes: source nodes, event nodes, and target nodes.

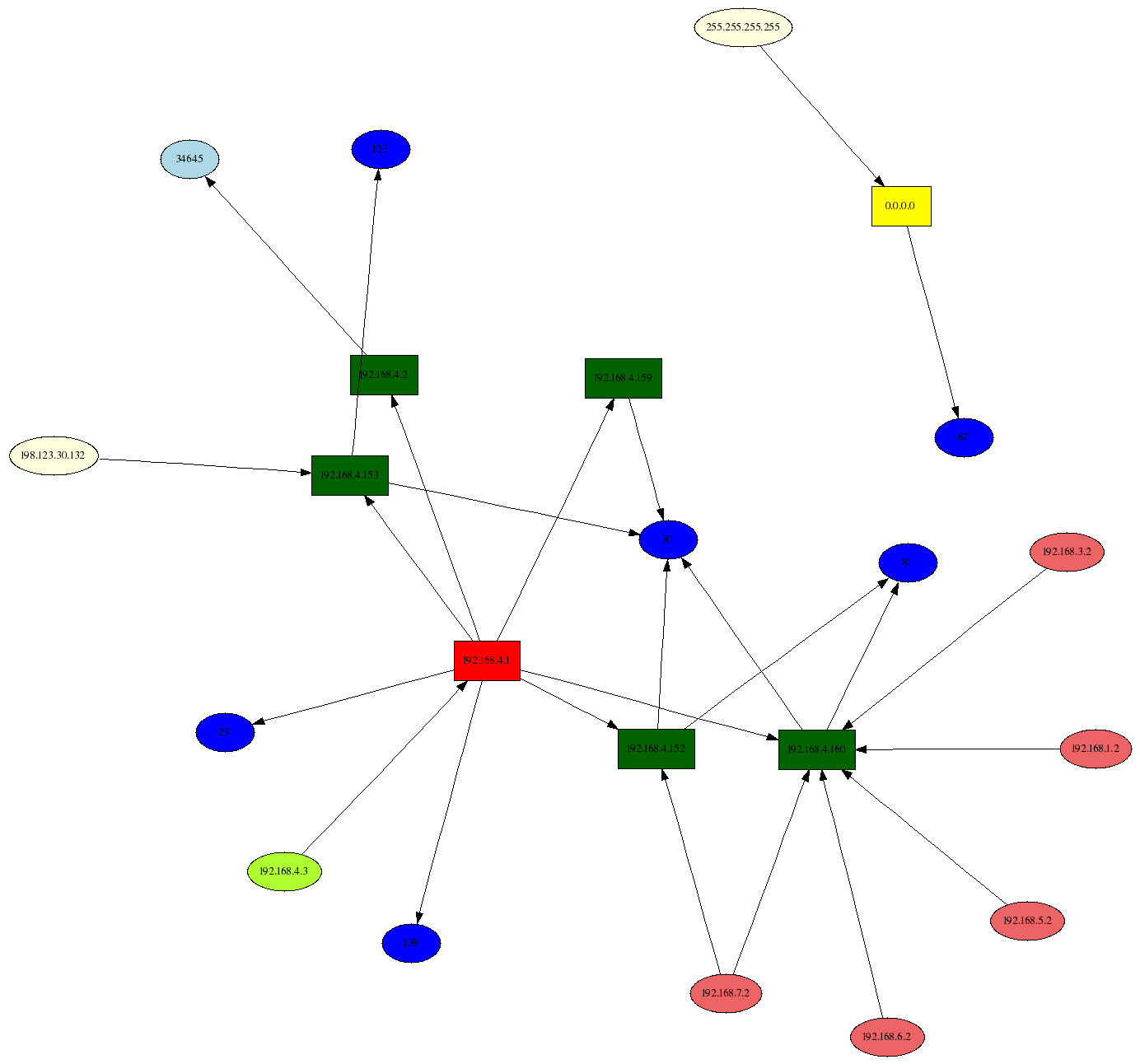
This lets me encode more information in a graph, such as the machines communicating and the service they used, as shown on the right.
All of this has been incredibly useful. However, for the longest time I have been thinking about how to include time into link graphs. To date, I don’t really have a good solution. Here are some things I have considered:
- Animation: This is the most obvious solution. You use a tool that replays the data. Use fast forward to speed up the animation. Ideally the tool would allow for forwarding and reversing the animation, just like the controls you have to watch a movie. This approach has the disadvantage of change blindness. There are changes that the human brain will not notice. And the probably even bigger problem are the layout algorithms that are generally not built for incremental updates. Adding new nodes to a graph moves the existing ones around and the viewer cannot locate them anymore. [I wrote about this in my book in Chapter 3.] You can counter the problem of instability by assigning each node a pre-computed location. Use some hashing algorithm to do so.
- Color: The idea would be to assign color to nodes or edges. Use some sort of encoding to show time. For example, the lighter a color, the late it happened. This approach is very limited. There are only so many colors you have available. The human eye can only differentiate, really differentiate about 8 hues. Any more and it gets really hard to tell which node is brighter. [It might be more than 8, but the number is really really low]
- Using arrows that order the connections: This was an idea I had a while back. I don’t think it’s actually useful, but here it is anyways: You generate a link graph and then you introduce a set of arrows that connect the edges. The arrows indicate time, so you connect the earliest event with the second earliest , and so on. This will really clutter the display an is probably really hard to read.
- Paralll coordinates: Add a coordinate for time. This can help in some instances. In others the time-axis will just be completely cluttered. But worth a try.
- Multiple, linked views: The idea here is to generate your link graph and then in addition, you also generate a display that encodes time. For example, a time table. On the x-axis you show time and on the y-axis you show, the source node’s field. The problem here is how do you link the two displays. Interactivity is almost a must. So that you could click on a node and see it in the time chart. Even better would be if you could encode the relationships in the time table. However, that might be hard.
- Using a time-base layout algorithm: I am too bad of a coder to actually implement this idea. I am also not sure what the result would be like. The idea would be to define the attraction between nodes as the time distance. There are many problems. What do you do if a connection shows up at multiple instances in time? I haven’t thought this true. But maybe there is a possibility here.
Unfortunately, all of these solutions have drawbacks. I think I favor timecharts for showing time-based activity. But then, the number of entities you can track is limited, etc.
Anyone have a solution for showing time-based activity? Even if it’s animation, what are some of the key things that would help making the animation easy to follow?
[tags]visualization, link graph, network graph, time visualization[/tags]
CISCO Router Forensics
I just came across this list of command to capture the state of a CISCO router. I wanted to capture this and maybe inspire someone to build an application for Splunk. It would be interesting to build a set of expect scripts that go out and capture this information in Splunk. You can then use the information for forensics, but also for change management. By building alerts you could even alert on unauthorized or potentially malicious changes. If you are interested in building an application, let me know. I’ be happy to help.
show clock detail show version show running-config show startup-config show reload show users show who show log show debug show stack show context show tech-support show processes show processes cpu show processes memory content of bootflash show ip route show ip ospf show ip ospf summary show ip ospf neighbors show ip bgp summary show cdp neighbors show ip arp show interfaces show ip interfaces show tcp brief all show ip sockets show ip nat translations verbose show ip cache flow show ip cef show snmp show snmp user show snmp group show snmp sessions show file descriptors
links for 2008-11-28
VizSec 2008 and Ben Shneiderman’s Keynote
 VizSec is a fairly academic conference that brings together the fields of security and visualization. The conference had an interesting mix of attendees: 50% came from industry, 30% from academia, and 20% from government. I had the pleasure of being invited to give a talk about DAVIX and also participate on a panel about the state of security visualization in the market place.
VizSec is a fairly academic conference that brings together the fields of security and visualization. The conference had an interesting mix of attendees: 50% came from industry, 30% from academia, and 20% from government. I had the pleasure of being invited to give a talk about DAVIX and also participate on a panel about the state of security visualization in the market place.
The highlight of the conference was definitely Ben Shneiderman’s keynote. I was very pleased with some of the comments that Ben made about the visualization community. First he criticized the same thing that I call the “industry – academia dichotomy”. In his words:
“[There is a] lack of applicability of research.”
I completely agree and if you have seen me talk about the dichotomy, I outline a number of examples where this becomes very obvious.
The second quote from Ben that I would like to capture is the following:
“The purpose of viz is insight, not pictures”
Visualization is about how to present data. I am not always sure that people understand that.
Unfortunately, I wasn’t prepared to capture what Ben said about my book (Applied Security Visualization.) He brought his copy that I had sent him. He talked about the book for quite a bit and specifically mentioned all the treemaps that I have used to visualize a number of use cases. I felt very honored that Ben actually looked at the book and had such great things to say about it. The following lunch with Ben was a great pleasure as well, filled with some really interesting visualization discussions.
The Process of Writing the Applied Security Visualization Book
 A little bit more than two years ago, I approached Jessica Goldstein from Addison Wesley to write a book about security visualization. We sat down during BlackHat 2006 and discussed my idea. It didn’t take much to convince her that they should get me on board. I went home after the conference and started putting together a table of contents. Here is the very first TOC that I submitted:
A little bit more than two years ago, I approached Jessica Goldstein from Addison Wesley to write a book about security visualization. We sat down during BlackHat 2006 and discussed my idea. It didn’t take much to convince her that they should get me on board. I went home after the conference and started putting together a table of contents. Here is the very first TOC that I submitted:
- Introduction
- Data Sources
- Visualization
- From Data To Visuals
- Visual Security Analysis
- Situational Awareness
- Perimeter Threat
- Compliance
- Insider Threat
- Data Visualization Tools
If you read the book, you will notice that this is pretty much what I ended up with. More or less. An interesting fact is that at the time of submitting the TOC, I had no idea what to exactly write about in the compliance and insider threat chapters. The even more interesting fact is that a lot of people told me that their favorite chapter is the insider threat chapter.
 After submitting the TOC to Jessica, she had me fill out some more marketing questions about the book. Things like target audience, competitive books, etc. After handing that in, it went silent for a bit. Jessica was selling the book internally. And then things started to look not so good. Jessica went on maternity leave. Kristin took over and got the proposal review process lined up. I asked some people in the industry to have a look over my proposal and provide feedback to the publisher. Questions like: “Why is Raffy the right person to write this book?” “Is there a market for this book?” etc. were being asked. I received the six really great reviews (thanks guys!) mid December 2006. On December 19th, I received an email with the contract to write the book. I sent the contract off to a friend of mine who is a lawyer, just because I was a bit worried about intellectual property rights. After a few emails also with Addison, I felt much better. They are not at all interested in any IP. They just want the copyright, which was totally fine with me. Then, finally, on January 17th, I signed and was under contract to write about 300 pages about security visualization.
After submitting the TOC to Jessica, she had me fill out some more marketing questions about the book. Things like target audience, competitive books, etc. After handing that in, it went silent for a bit. Jessica was selling the book internally. And then things started to look not so good. Jessica went on maternity leave. Kristin took over and got the proposal review process lined up. I asked some people in the industry to have a look over my proposal and provide feedback to the publisher. Questions like: “Why is Raffy the right person to write this book?” “Is there a market for this book?” etc. were being asked. I received the six really great reviews (thanks guys!) mid December 2006. On December 19th, I received an email with the contract to write the book. I sent the contract off to a friend of mine who is a lawyer, just because I was a bit worried about intellectual property rights. After a few emails also with Addison, I felt much better. They are not at all interested in any IP. They just want the copyright, which was totally fine with me. Then, finally, on January 17th, I signed and was under contract to write about 300 pages about security visualization.
After a few days, I received an ISBN number for the book and a ton of material about style guides and how to go about writing the book. All very exciting. I decided to not write my book in TeX, unlike my masters thesis. That was definitely a smart decision. It turned out that using Word wasn’t that bad. The template from Addision made it really easy to format the text correctly. I actually ended up using VI to write the original text without any formatting. Once it was all done, I copied the raw text into Word and started formatting. The reason for doing this is that I am so much quicker in VI than I am in Word. (And hitting the ESC key in Word is not something you want to be doing too much.)
 One of the next steps was to put together a timeline. Well, it was sort of aggressive. The version of the schedule I could find in my archives shows that I was planning on being done mid September 2007. Well, I missed that by only a year 😉 I attribute a lot to the fact that I didn’ really know how to write (seriously) and to the chatpers for which I had to do a lot of research.
One of the next steps was to put together a timeline. Well, it was sort of aggressive. The version of the schedule I could find in my archives shows that I was planning on being done mid September 2007. Well, I missed that by only a year 😉 I attribute a lot to the fact that I didn’ really know how to write (seriously) and to the chatpers for which I had to do a lot of research.
I definitely enjoyed the process of writing the book. The folks at Addison Wesley were awesome. They kept motivating me along the way and provided great insights into the writing process. What I am still very impressed with is the PR aspects. Early on, they hooked me up to film a video cast about the book. After publishing the book, I get about an email a week for some press opportunity. Keep them coming 😉
Here is a fun fact: In ~/Data/projects/vis_addision, where I have all the material for the book, I accumulated 1.1GB of data. Pretty crazy.

 Are you thinking about writing a book? Do it, but make sure you have time! I spent a LOT of time in the local coffee shop (picture on the left). I always had printouts with me to work on corrections. The picture on the right I took at 6.30am in Taipei. Yes, it’s a full-time job! I learned a lot! I made amazing connections. And I had fun! One piece of advice: make sure you have a good publisher!
Are you thinking about writing a book? Do it, but make sure you have time! I spent a LOT of time in the local coffee shop (picture on the left). I always had printouts with me to work on corrections. The picture on the right I took at 6.30am in Taipei. Yes, it’s a full-time job! I learned a lot! I made amazing connections. And I had fun! One piece of advice: make sure you have a good publisher!
I haven’t seen the book in my local Barnes and Nobles yet. Well, I checked two weeks ago. But a friend (@jjx) sent me this picture. So, apparently some book stores have it in stock:

FIT-IT Gesucht: Sicheres und Sichtbares
 Next Tuesday I will be speaking in Graz, Austria at the FIT-IT event. The topic of the event is Trust in IT Systems & Visual Computing. I am giving a keynote in the afternoon about the topic of Security Research 2.0. I will be hitting on one of my favorite topics, the dichotomy between security and visualization. We need to all work hard on combining the worlds of visualization and the security. We have all seen what happens if security people are writing visualization tools. And we have seen what happens when visualization people try to understand networking and security. I can show you some pretty bad papers that get either side completely wrong. Maybe I am just too picky, but if you read some of the papers that I reviewed for RAID and VizSec, you would probably agree with me.
Next Tuesday I will be speaking in Graz, Austria at the FIT-IT event. The topic of the event is Trust in IT Systems & Visual Computing. I am giving a keynote in the afternoon about the topic of Security Research 2.0. I will be hitting on one of my favorite topics, the dichotomy between security and visualization. We need to all work hard on combining the worlds of visualization and the security. We have all seen what happens if security people are writing visualization tools. And we have seen what happens when visualization people try to understand networking and security. I can show you some pretty bad papers that get either side completely wrong. Maybe I am just too picky, but if you read some of the papers that I reviewed for RAID and VizSec, you would probably agree with me.
While talking about RAID and VizSec, the conferences are taking place in a week at MIT in Boston. I will be giving a short presentation on DAVIX with Jan Monsch and will also be part of a panel discussion. Looking forward to make my points about visualization there. I am going to stay for RAID and hope to catch up with my former collegues from IBM research. Drop me a note if you are attending as well.
Applied Security Visualization Press
 I recorded a couple of podcasts and did some interviews lately about the book. If you are interested in listening in on some of the press coverage:
I recorded a couple of podcasts and did some interviews lately about the book. If you are interested in listening in on some of the press coverage:
- Security Wire Weekly: Security Visualization, Interview with Robert Westervelt from TechTarget.
- Networking data visualization not just for pointy-headed bosses, Interview with Michael Morisy
More information about the Applied Security Visualization book is on the official book page. I am working on figuring out where to put an Errata. There were some minor issues and typos that people reported. If you find anything wrong or you have any generic comments, please let me know!
First Amazon for Applied Security Visualization Book
I just saw the first Amazon review for my book. I just don’t understand why the person only gave it four stars, instead of five 😉 Just kidding. Thanks for the review! Keep them coming!